


18.06.2019
in Technology
Nun mal Backup bei die Fische
Inhaltsverzeichnis
Backup: Does it spark joy?
Das Wort “Datensicherung” verursacht bei vielen Beteiligten nicht gerade Jauchzen und Frohlocken. Dass dies nicht so sein muss, zeigt diese Artikelserie über das Softwarepaket “restic”. Restic erleichtert viele Aspekte von Backup und Restore so weit, dass man sich auf das Wesentliche konzentrieren kann: Dem unterliegenden Systemaufbau.
In dieser Artikelserie wird beschrieben, wie man restic konfiguriert und Daten sichert. Der zweite Teil der Serie wird sich mit der Wiederherstellung von Daten und der Entrümpelung alter Sicherungen beschäftigen. Der Autor ist sich sicher: Die Fernsehaufräumkönigin Marie Kondō (“Does it spark joy?”) würde sich mit restic gut zurechtfinden.
Um den Zusammenhang zu veranschaulichen, werden ein Hostsystem und zwei Docker-Container verwendet: Ein Container, um ein entferntes Backup-Medium zu simulieren, und ein anderen Container, um die Nutzlast eines Containers darzustellen, dessen Daten gesichert werden sollen (mehr dazu später).
Designziele
Bereits beim ersten Betrachten erweckt restic einen strukturierten Eindruck. Die Homepage behauptet von sich: “Backup done right”, ein Wahlspruch, dem der Autor zuspricht. Den Hintergrund bietet die Vergangenheit der Computerei: Mit steigender Systemkomplexität wird eine ungesteuerte Herangehensweise an das Thema schnell übermächtig. Restic begegnet diesem Umstand mit Einfachheit und Schnelligkeit. Sicherungen, die zu kompliziert sind, werden vermieden. Hierbei setzt restic auf eine einfache Kommandosyntax, stabile Datenstrukturen und einfache Konfiguration.
Da gleichfalls Sicherungen gemieden werden, deren Durchführung zu lange dauert, ist Geschwindigkeit ein weiteres Designziel. Schnelligkeit erreicht restic dadurch, dass erst Prüfsummen der zu sichernden Daten gebildet werden. Diese Daten werden in ein sogenanntes Repository übertragen, das den Ablageort der Sicherung darstellt. Dies geschieht aber nur für die Teile, die noch nicht vorhanden sind. Dies führt zu der Möglichkeit der Deduplikation von Daten. Nur selten unterscheidet sich ein Systemzustand vollständig von einem späteren Systemzustand. Diesen Umstand macht sich restic zu Nutze und ermittelt auch dies bevor ein Datenpaket in das Repository eingebracht wird.
Fast wichtiger als die Sicherung selbst ist die Wiederherstellung von Sicherungen. Das Prinzip Hoffnung ist hier ein schlechter Ratgeber, denn eine Sicherung ist nur dann brauchbar, wenn alle gesicherten Daten auch wiederherstellbar sind. Der einzige Weg lautet hier, die Verifizierung der gesicherten Daten in den Workflow zu übernehmen. Auch hier ist Einfachheit König, wie später in dem Teil gezeigt wird, der sich mit Wiederherstellung beschäftigt.
Ein schöner Aspekt an der Sicherung mit restic ist die mitgelieferte Verschlüsselung, die sogar standardmäßig verwendet wird. In Zeiten einer potentiell unsicheren Ablage in der Cloud ist dies ein absoluter Pluspunkt, da der häufig vorgelagerte Prozessschritt der Verschlüsselung zugunsten einer Verschlüsselung im Industriestandard entfällt. Dazu enthält das Paket bereits Anbindungen zu relevanten Speicherpunkten, wie etwa SFTP, S3 oder ins lokale Dateisystem.
Installation
Restic lässt sich über vielerlei Quellen beziehen. Sei es als Download von GitHub, als Paket der großen Linux-Paketmanager, Docker-Image oder man kompiliert selbst (dank der Crosscompiler-Fähigkeit ist die Installation von Go sehr einfach). Hierbei wird eine Vielzahl von Betriebssystemen unterstützt. Um das Vorgehen zu veranschaulichen, liefert in diesem Beitrag der Webserver nginx statische Webseiten aus, die gesichert werden sollen. Später werden diese Seiten mit restic gesichert und auch wiederhergestellt.
Da in diesem Beitrag mit Docker gearbeitet wird, wird vorausgesetzt, dass der Benutzer mit root-Rechten arbeitet, um später Docker Volumes auslesen zu dürfen. Dies ist jedoch keine grundsätzliche Voraussetzung für die Arbeit mit restic.
Wie benutzt man restic?
Wie viele Programme aus dem Bereich der Cloud-Technologie akzeptiert restic Kommandos, um bestimmte Aktionen auszuführen. Dabei handelt es sich um Kommandozeilenparameter, die restics Funktionsweise je nach Anwendungsfall abwandelt. Diese Kommandos akzeptieren oder verlangen ihrerseits Argumente. Restic gibt auf jeder Kommandoebene mittels dem --help-Argument weitere Informationen darüber, welche Argumente akzeptiert werden, z. B. restic --help oder restic backup --help
Für diesen Artikel interessante Kommandos sind:
initzum Anlegen eines Backup-Repos,snapshotszum Anzeigen existierender Sicherungen,backupzum Sichern von Dateien und Verzeichnissen
Backup-Repository einrichten
Bevor mit dem Sichern begonnen wird, sollten in aller Kürze grundsätzliche Verhaltensweisen und Begriffe erklärt werden.
Das restic Repository ist der Ort, an dem die verschlüsselte Sicherung aufbewahrt wird. Bekäme ein Angreifer diese Daten in die Hände, so könnte er mit ihnen aufgrund der Verschlüsselung nichts anfangen.
Restic abstrahiert einzelne Sicherungsvorgänge in Snapshots, deren Sicherung parallel ablaufen können. Wenn man beispielsweise den Pfad /etc/ sichern möchte, dann werden mehrere Dateien darin parallel in einem Snapshot in dem Repository abgelegt. Jeder Snapshot besitzt eine eindeutige Snapshot ID, über die auf diesen Snapshot zugegriffen werden kann. Darüber hinaus ist es möglich Tags an Snapshots anzufügen, um damit Snapshots für die eigene Arbeit zu gruppieren oder zu filtern.
Im Folgenden wird das S3-Protokoll ausgewählt, um eine Sicherung in AWS oder Google Buckets abzubilden. Die Konfiguration hierzu besteht lediglich aus vier Umgebungsvariablen. Alternativ sind auch Kommandozeilenargumente möglich. Dies ist aber gerade im Cloud-Kontext eher unüblich, bei dem verstärkt mit vergänglichen Umgebungsvariablen gearbeitet wird. Diese Umgebungsvariablen können dann später über den Host an den Container übergeben werden. Um reibungslos Docker verwenden zu können, werden einer Shell root-Rechte eingeräumt. Diese root-Shell wird in den folgenden Beispielen immer wieder weiterverwendet.
sudo su
export AWS_ACCESS_KEY_ID="AKIAIOSFODNN7EXAMPLE"
export AWS_SECRET_ACCESS_KEY="wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY"
export RESTIC_REPOSITORY="s3:http://127.0.0.1:9000/backuprepo"
export RESTIC_PASSWORD="3 weird tricks to gain Ops attention..."
Als nächstes soll nun das Repository angelegt werden. Zu Testzwecken wird ein entwicklerfreundlicher Ersatz benötigt, der in der Produktionsumgebung durchaus ein AWS S3 Bucket oder Google Bucket sein kann. Hierbei bietet sich MinIO object storage server an, der mit AWS S3 kompatibel ist. Für den Namen des S3 Buckets gelten die üblichen Namensregeln. Alternativen hierzu werden im zweiten Teil dieser Serie genannt.
Zu beachten ist: Die in dem Container gespeicherten Sicherungsdaten werden mit Erlöschen des Containers ebenfalls gelöscht.
docker run --detach -p 9000:9000 --name minio \
-e "MINIO_ACCESS_KEY=${AWS_ACCESS_KEY_ID}" \
-e "MINIO_SECRET_KEY=${AWS_SECRET_ACCESS_KEY}" \
minio/minio server /data
# Warten bis der Container sich mit healthy zurückmeldet
Nun kann endlich das restic Repository einmalig initialisiert werden. Da bereits alle Umgebungsvariablen gesetzt sind, weiß restic wo das Repository liegen und mit welchem Schlüssel es verschlüsselt werden soll.
restic init
created restic repository 00d7d2bb57 at s3:http://127.0.0.1:9000/backuprepo
Please note that knowledge of your password is required to access
the repository. Losing your password means that your data is
irrecoverably lost.
Damit ist das restic Repository bereit für die Benutzung. Die erste Sicherung kann gestartet werden. Damit Daten vorhanden sind, wird als nächstes eine simple Webseite als Pseudo-Inhalt in einem Docker Volume erzeugt. Diese Webseite wird dann durch nginx unter http://localhost:8080 ausgeliefert. Dieser Inhalt steht hier nur exemplarisch für sämtliche Nutzdaten eines Containers.
docker volume create nginxData
# erzeugt aus der restic manpage eine HTML-Seite
docu=$(man restic) && echo "<pre>${docu}</pre>" | tee /var/lib/docker/volumes/nginxData/_data/index.html
docker run --name prod-nginx -v nginxData:/usr/share/nginx/html:ro -p 8080:80 -d nginx
Sichern
Mit einem initialisierten restic Repository könnte man nun sofort loslegen und Dateien und Verzeichnisse sichern. Allerdings muss einerseits restic auf die Dateien und Verzeichnisse auch zugreifen können, um sie zu sichern. Andererseits darf die Sicherung nicht in sich korrumpiert sein. Dies könnte der Fall sein, wenn ein Container auf mehrere Dateien sequentiell schreibt, diese Transaktion jedoch noch nicht beendet hat und dann das Backup zuschlägt.
Um nun ordentlich die Sicherung durchzuführen, muss folgendes geschehen:
- den Container stoppen
- das Volume(s) sichern
- den Container starten
Für den frisch befüllten nginx-Container aus dem Volume würde dies so aussehen:
docker stop prod-nginx
prod-nginx
restic backup /var/lib/docker/volumes/nginxData
repository 00d7d2bb opened successfully, password is correct
Files: 3 new, 0 changed, 0 unmodified
Dirs: 4 new, 0 changed, 0 unmodified
Added to the repo: 0 B
processed 3 files, 4.986 KiB in 0:00
snapshot 40b3ab4c saved
docker start prod-nginx
prod-nginx
Mit restic snapshots lassen sich die angelegten Snapshots anzeigen.
Nun wird es Zeit, die wirklichen Bedingungen anzuschauen.
Fachlichkeit in der Sicherung betrachten
Das Unbehagen von Sicherungen und Wiederherstellungen kann durch unterschiedliche Dinge verursacht werden: Es kann an dem Unwissen liegen, ob eine Wiederherstellung funktionieren würde. Aber auch die Komplexität eines Computersystems mit offenen und gesperrten Dateien oder gleichzeitigen Schreibzugriffen vermiesen einem gewillten Administrator häufig diesen Auftrag.
Um Letzteres zu Lösen, besteht der erste Schritt darin, Abhängigkeiten zu identifizieren und zu entkoppeln, etwas das im Umfeld von Docker bereits geschieht. Container bilden bereits ihre eigene Entkopplung. Um schnell gestartet und gestoppt zu werden, dürfen die Daten des Containers ohnehin nicht direkt im Container vorliegen, sondern über Volumes eingebracht werden (siehe Inofbox am Ende des Posts). Damit ein möglicher Schreibzugriff und sonstige Dateisperrungen nicht im Wege sind, sollten nun alle Container, die auf dieses Volume zugreifen, gestoppt werden.
Es bleibt noch das Hostsystem übrig, das seinerseits eventuell Dateien offen halten könnte. Ist dies der Fall, sollte ein Mechanismus geschaffen werden, gezielt den Zugriff auf die zu sichernden Daten zu stoppen und wieder zu starten. Da dies von System zu System unterschiedlich ist, wird in dieser Artikelserie nicht weiter darauf eingegangen.
Sollten mehrere Container fachlich voneinander abhängen, etwa eine Applikation und eine Postgresql-Datenbank, dann müssen diese in der richtigen Reihenfolge und nach ihrem jeweiligen eigenen Maßstäben gesichert werden. Postgresql hat z. B. andere Sicherungsmechanismen als ein nginx mit statischen HTML-Dateien.
Interessant wird es dann, wenn mehrere fachliche Teile zu einem Sicherungsvorgang gehören die technisch aber getrennt in zwei unterschiedlichen Docker-Container liegen. Beide Container werden für die Datenhaltung Volumes besitzen. Wenn in solch einer Konstellation nur eines der beiden Volumes wiederhergestellt wird, dann wird voraussichtlich eine Inkonsistenz über beide Container auftreten.
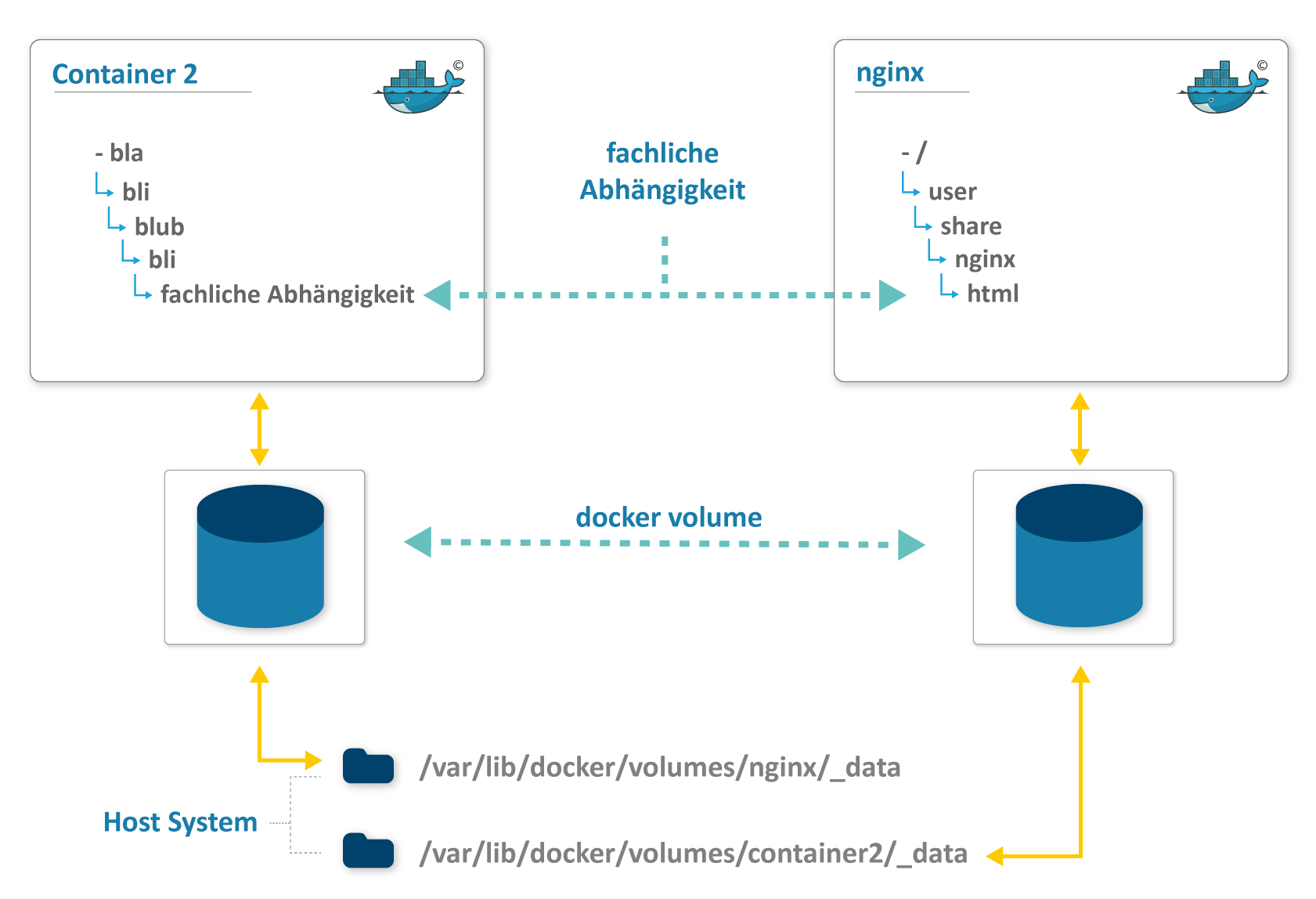
In diesem Fall besteht lediglich eine fachliche Abhängigkeit zwischen beiden Containern. Eine konsequente Lösung besteht darin, während Sicherung und Wiederherstellung diese Abhängigkeit ebenfalls abzubilden:
- beide Container herunterfahren
- beide Volumes sichern
- beide Container wieder hochfahren
Ordnung ist das halbe Leben
Wird erst einmal erfolgreich gesichert, gesellt sich schnell der Wunsch dazu, einer Sicherung einen Kontext zu geben. Hierbei kann für unterschiedliche Snapshots das gleiche Tag gesetzt werden, um die obige, fachliche Abhängigkeit auszudrücken. Darüber hinaus besteht die Möglichkeit, mehrere Tags für einen Snapshot zu vergeben.
restic backup /var/lib/docker/volumes/nginxData --tag "Komplettsicherung KW16"
restic backup /var/lib/docker/volumes/container2 --tag "Komplettsicherung KW16"
Dies drückt auch die Snapshot-Übersicht aus:
restic snapshots
repository 00d7d2bb opened successfully, password is correct
ID Date Host Tags Directory
-------------------------------------------------------------------------------------------------------------
d7e6092d 2019-04-12 15:52:32 MY-HOST-1337 Komplettsicherung KW16 /var/lib/docker/volumes/nginxData/_data
dd6ad91c 2019-04-12 15:54:57 MY-HOST-1337 Komplettsicherung KW16 /var/lib/docker/volumes/container2/_data
-------------------------------------------------------------------------------------------------------------
2 snapshots
Alles, was wir sind, sind Container im Wind
Ein Container stellt ein instanziiertes Image dar. Der ideale Container muss klein, schnell und zustandslos sein, damit der Container entbehrlich bleibt. Dies bietet eine Vielzahl an Vorteilen in der Verteilung der Images sowie beim Rollout. Kleine Images lassen sich schnell beziehen, z. B. wenn aus einem neuen Image ein Container erstellt werden soll, das Image aber noch nicht im Cache liegt.
Wichtig für das Backup und Restore ist aber der Umstand, dass ein Container keinen Zustand besitzen sollte. Andernfalls würde dies die Entbehrlichkeit deutlich behindern, wenn bspw. der Container einfach abgeschossen wird. Die Imagegröße steigt dadurch merkbar und die I/O-Effizienz lässt deutlich nach (siehe Docker Best Practices).
Daher müssen die verwendeten Daten extern gespeichert werden. Dies kann über Container Volumes oder über Aufrufe zu einer Datenbank geschehen. Die Datenbank muss dann ihrerseits die DB-Daten auf dem Host ablegen, um denselben Ansprüchen an einen Container zu genügen.
Der Container selbst muss nicht gesichert werden, denn er liegt bereits in dem Repository, aus dem das Container-Image bezogen wurde. Sofern das Container-Image-Repository nicht gesichert wird, wie es bspw. bei Docker Hub, AWS ECR geschieht, so kann dies ebenfalls über den hier vorgestellten Mechanismus geschehen.
Besuchen Sie unsere Community-Plattform, um Ihre Ideen zu teilen, Ressourcen herunterzuladen und auf unsere Schulungen zuzugreifen.
Jetzt mitmachen

