



Experts in Software Lifecycle Management and process automation, supporter of open source software and developer of the Cloudogu EcoSystem.
This article is part 5 of the series „Jenkins Pipeline for continuous delivery“
Read the first part now.
Continuous delivery (CD) is an agile software development approach that has proven to be a suitable way to reliably and repeatably produce high-quality software in short cycles. The use of containers and the cloud, e.g., on platforms such as Kubernetes (K8s), offers many opportunities to make CD processes more robust and simpler. One such option is GitOps. This article provides some concrete examples to illustrate the differences between classic CD pipelines (CIOps) and GitOps processes.
CD automation is done using pipelines on continuous integration (CI) servers, such as Jenkins. There are two use cases where the use of containers provides advantages:
These images can be deployed in many different operating environments, since the Open Container Initiative (OCI) has standardized both Docker containers and images as well as the registry API. In recent years, container orchestration platforms have proven to be a flexible tool for deploying OCI images, especially in the DevOps environment. K8s has emerged as a de facto standard, which is why this article focuses on the example of deployment to K8s.
In the case of a “classic” CD pipeline, the CI server actively performs the deployment to the operating environment (see Figure 1). In order to distinguish it from more recently developed methods, such as GitOps (see below), this procedure is also referred to as “CIOps.” Sometimes it is represented as an anti-pattern. However, the procedure has proven its worth in practice for many years, and, in general there’s nothing wrong with it.
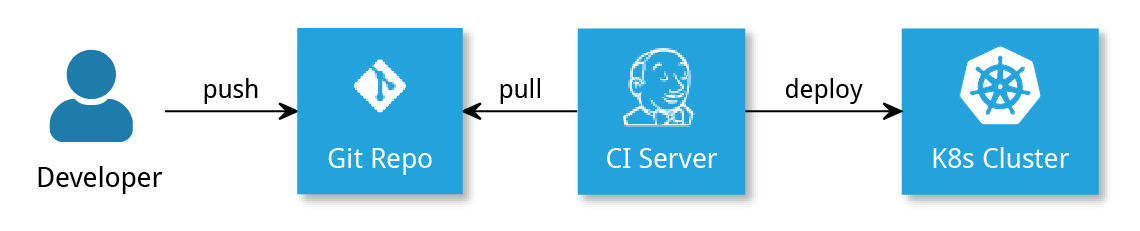 Figure 1: Classic CD pipelines (CIOps)
Figure 1: Classic CD pipelines (CIOps)
An easy-to-implement logic for automating deployment in a CIOps pipeline with staging and production environments is the use of branches in Git. In adopting this approach, many teams use feature branches or Git Flow, where the integrated development level flows together in the develop branch, and the main (or master) branch contains the productive versions. It can be used as a basis for a CD strategy: every push to develop leads to a deployment in the staging environment, every push to main goes into production. Thus, the last integrated version in staging is always available for functional or manual testing. A pull request (PR) or merge to main then initiates the deployment to production. Furthermore, it is possible to have a deployment per feature branch.
The disadvantage of this approach is that each deployment requires a build in the CI server. That slows down the process because the same artifact is supposed to be deployed to all the stages. So no new build, test, or even version name would be necessary. This deployment logic is easy to implement with Jenkins Pipeline, because the branch name can be queried from the environment in multibranch builds. A detailed example showing a full implementation with Jenkins is described in in this post; the full Jenkinsfile can be viewed on GitHub.
There is now an alternative to CIOps in the K8s environment: GitOps. Here, a cloud-native application running in the K8s cluster (the “GitOps operator”) continuously compares the actual state of the cluster with the desired state described in a Git repository. Deployments are triggered by a push to this repository, such as by accepting a PR (see Figure 2). There are a few advantages to GitOps:
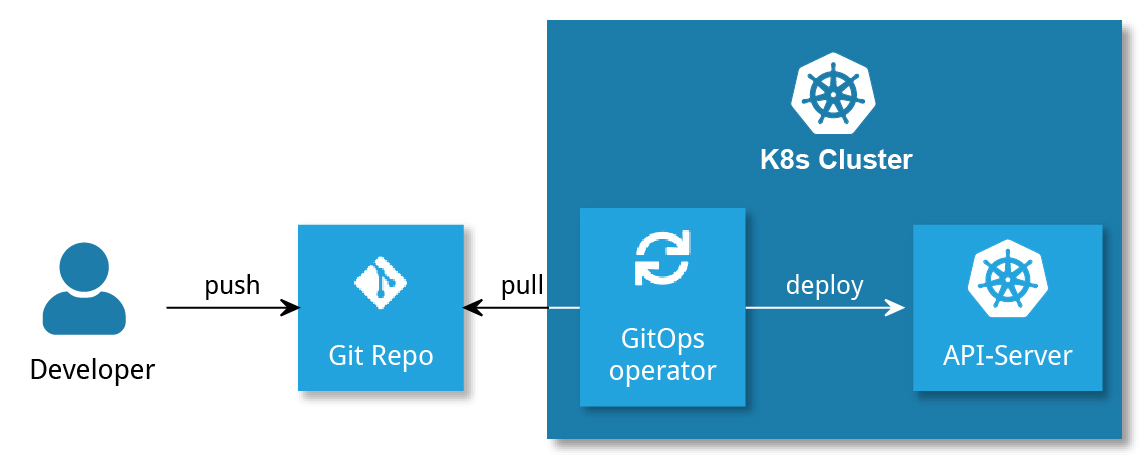 Figure 2: Simple deployment using GitOps
Figure 2: Simple deployment using GitOps
A CI server is no longer necessary to deploy third-party applications (not developed in-house). Applications written in-house still must be built, tested, etc. This is still done using a CI server, just like pushing the image to a registry (see Figure 3). Moreover, the CI server can be used to solve some of the challenges of GitOps:
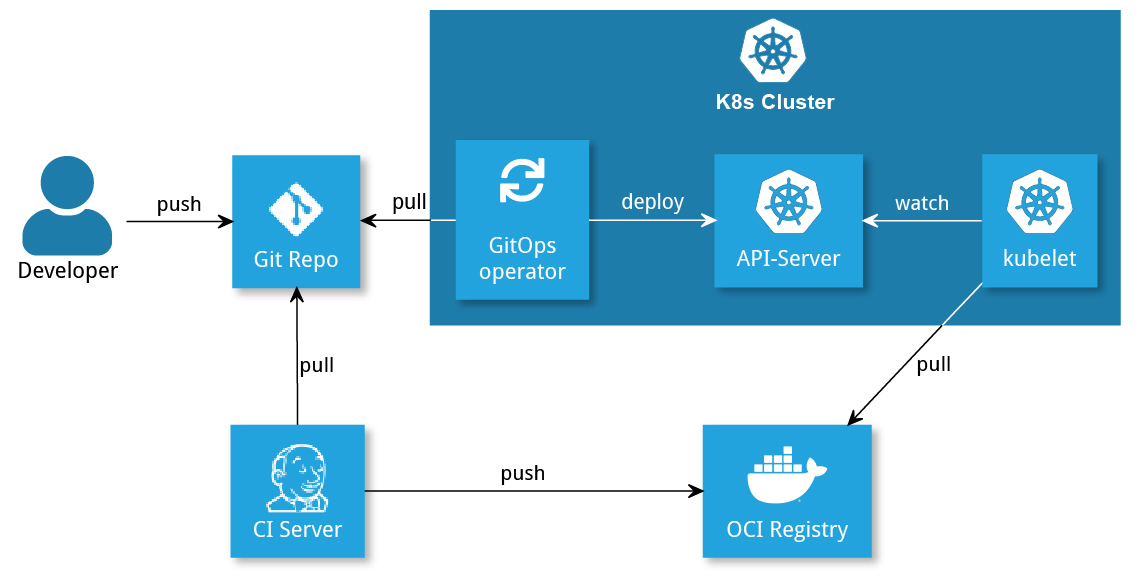 Figure 3: GitOps deployment of in-house developed images
Figure 3: GitOps deployment of in-house developed images
It is possible to use the CI server to keep both in the application’s repository (hereinafter referred to as the app repository). The CI server cab be used to push the infrastructure code to the GitOps repository (see Figure 4).
Learn all the important basics about the implementation of GitOps, details about operators and how to use it to operate a Kubernetes cluster in our training.
To the trainingThe implementation of a GitOps flow, as shown in Figure 4, may seem very easy to implement at first glance. But, as is so often the case, the devil is in the details: On the one hand, implementation challenges need to be addressed, and, on the other hand, other points quickly crop up that can be automated by the pipeline. In the end, the initially simple implementation of such a pipeline can quickly become costly.
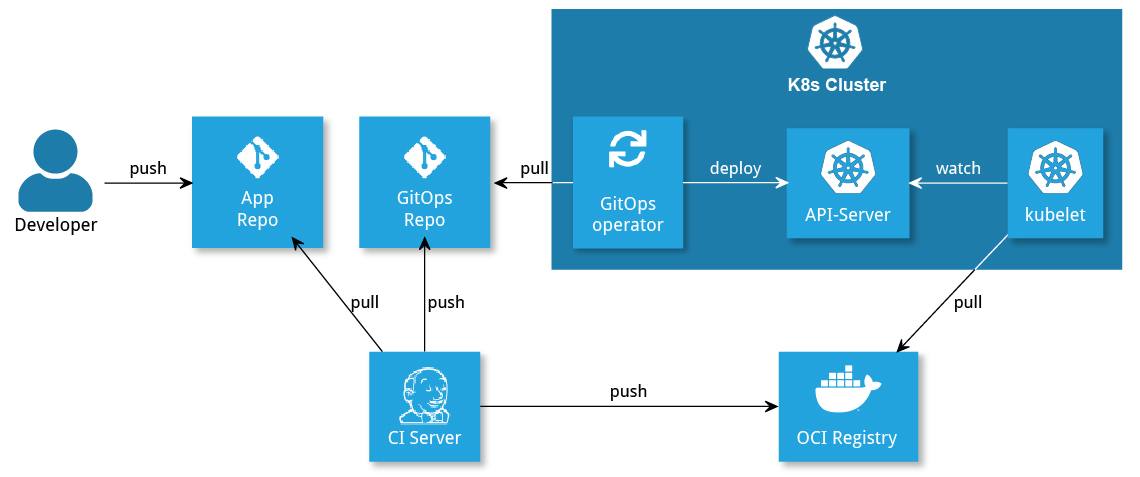 Figure 4: Deployment with app repository and GitOps repository
Figure 4: Deployment with app repository and GitOps repository
The biggest challenge is that multiple builds that write to the same GitOps repository can run concurrently. Reliably handling such concurrency issues is a surprisingly complex task. Once the pipeline is basically functioning, further automation can make the development process more efficient. Examples of such extensions will follow later.
Concrete examples of GitOps flows are provided by the GitOps Playground, which allows you to try out various GitOps operators, such as Flux (GitOps Toolkit) and ArgoCD (GitOps Engine), in a locally executable cluster in conjunction with Jenkins.
It also includes a Jenkins Pipeline (Before extracting to library; after extracting to library) that is similar to the CIOps example that was already mentioned. However, the pipelines differ fundamentally from each other in two respects:
Figure 5 shows the basic folder structure of the GitOps repository: At the top level, there is one folder per stage. Each of which contains one folder per application. The deployment then differs slightly depending on how the stages are solved:
 Figure 5: Possible folder structure of a GitOps repository
Figure 5: Possible folder structure of a GitOps repository
The flow of the mentioned pipeline from the GitOps Playground is as follows:
After this pipeline has been completed, the application is deployed to staging by the GitOps operator for review. Moreover, there is a PR that leads to direct deployment in production (without a CI server) when accepted.
The concurrency issues described above can occur between cloning the repository and the pushes: If the remote repository has been changed in the meantime, the push fails, causing the build to fail. This complicates and slows development, so the pipeline in the example has a simple retry mechanism. If the push fails, there is a pull and a new push. This solution is not perfect, because the build still fails in the event of conflicts. In certain circumstances, an inconsistency may even occur: the pull could make a fast-forward merge that combines the changes from the build with those from another one. It would, therefore, be safer to not push after the pull, but to reset to the remote version and make the changes again. When it comes to other points, the pipeline is already quite sophisticated. For example, the commits the job made to the GitOps repository are displayed in the Jenkins job description for more transparency. To make reviewing the PR more efficient, the following is written in the commit message in the GitOps repository (Figure 6 shows this with SCM-Manager as an example):
 Figure 6: Example of a commit created by the CI server in the GitOps repository
Figure 6: Example of a commit created by the CI server in the GitOps repository
There are other features currently being developed in the GitOps Playground that make the process more efficient. They may already be available at the time this article is published:
yamlint tool, for example. Another step is to check the K8s resources against the K8s schema. This can be done using the kubeval tool. If the Helm charts have their own schema, then the latter can also be tested (using helm lint).The presented CIOps and GitOps examples show how simple K8s resources can be applied to the cluster using the respective method. The disadvantage of this is that the K8s resources must be stored completely redundantly for each stage. Therefore, in practice, templating tools are often used to allow a single source (without redundancy) to be configured. Helm, the official package manager for K8s, is a common solution. Helm can be used to do more than deploy third-party packages. Its templating function can also be used for local development.
There are some alternatives to Helm for local development, such as the “template-free” tool Kustomize, which works with overlays that are applied to a base file using the patching mechanism.
CIOps makes it relatively easy to use templating tools. The tools are available through a command-line interface that can be called in the pipeline. An example of this is available on GitHub. Here, the Helm binary is executed as a container, which means that there is no need to configure the Jenkins controller. Some other valuable practical findings:
helm upgrade --install eliminates the need to make a complex distinction between the initial installation and upgrades.values.yaml contained in all Helm packages (which are called charts), describes default values; another values file per stage sets the respective specific values. The –-values parameter must be used to pass this file to the Helm command; the default values.yaml is always used implicitly.--set 'image.tag=...When you start using templating tools with GitOps, you face one daunting challenge: How can the imperative call (for example, helm upgrade) be put into a declarative form that can be placed in the GitOps repository? The solution: by using additional operators in K8s. For the widely used tools Helm and Kustomize, such operators already exist, but this is not necessarily the case for other templating tools. Here, too, there is a practical example that you can find in the GitOps Playground (Before extracting to library; after extracting to library). It delivers a static HTML page using the NGINX web server. This example would also work without a pipeline, but with the disadvantages mentioned above:
In this respect, the use of a pipeline is also advantageous for the GitOps deployment of third-party applications. Looking at the two Jenkinsfiles in the GitOps Playground, it is striking that the pipelines for the two different use cases “K8s resources” and Helm are largely the same. Here, extraction into a Jenkins shared library allows for reuse and less maintenance in Jenkins pipelines. This lead to the development of the GitOps-build-lib, which is now home of the pipeline logics described in this article.
Finally, it should be noted that using a Helm operator can have advantages even without GitOps: The source and version of the chart are declared as IaC (in YAML) instead of within a Jenkinsfile. This is simply applied to the cluster. The pipeline no longer requires a Helm binary. The same procedure also works for local development.
There is no question that CD provides added value. This article uses CD implementation examples with K8s and Helm deployment to show that it is quite possible to use Jenkins for implementation with both CIOps and GitOps. So the answer to the “CIOps or GitOps” question lies in the implementation details. Both can work well in practice. If you already have existing CD processes, you should only switch if the advantages of GitOps provide significant added value in your individual use case. You should not underestimate the amount of migration effort that will be required: If you have a lot of pipelines, you will also have to migrate a lot of pipelines. For newcomers, it is a good idea to start directly with GitOps due to its numerous advantages. However, this makes the already steep learning curve even steeper. The full examples can be found on GitHub in the repositories for CIOps and GitOps. This article did not consider the differences between various GitOps operators. That is an issue in itself. A first step to approaching this in practice can be to visit the GitOps Playground or our post about GitOps tools that also compares Flux and ArgoCD.
Visit our community platform to share your ideas with us, download resources and access our trainings.
Join us now
This article is part 5 of the series „Jenkins Pipeline for continuous delivery“.
Read all articles now:


