



Experten für Software-Lifecycle-Management und Prozessautomatisierung, Förderer von Open-Source-Software und Entwickler des Cloudogu EcoSystem.
Continuous Delivery (CD) hat sich im Umfeld agiler Softwareentwicklung als adäquates Vorgehen erwiesen, qualitativ hochwertige Software in kurzen Zyklen zuverlässig und wiederholbar zu veröffentlichen. Der Einsatz von Containern und Cloud, beispielsweise auf Plattformen wie Kubernetes (K8s), bietet viele Möglichkeiten, um CD-Prozesse robuster und einfacher zu gestalten. Eine solche Möglichkeit ist GitOps. In diesem Artikel werden die Unterschiede zwischen klassischen CD-Pipelines (CIOps) und GitOps-Prozessen anhand von konkreten Beispielen aufgezeigt.
Die Automatisierung bei CD erfolgt mittels Pipelines in Continuous-Integration-(CI)-Servern wie Jenkins. Dabei gibt es zwei Anwendungsfälle, bei denen der Einsatz von Containern Vorteile bietet:
Diese Images können auf vielen verschiedenen Betriebsumgebungen deployt werden, da mittlerweile sowohl Docker-Container und Images als auch das API der Registry durch die Open Container Initiative (OCI) standardisiert sind. In den letzten Jahren haben sich besonders im DevOps-Umfeld Container Orchestration Platforms als flexibles Mittel für Deployments von OCI-Images erwiesen. Dabei hat sich K8s als De-facto-Standard herauskristallisiert, weshalb sich dieser Artikel exemplarisch auf das Deployment auf K8s beschränkt.
Bei einer „klassisch“ umgesetzten CD-Pipeline führt der CI-Server aktiv das Deployment in die Betriebsumgebung durch (siehe Abbildung 1). Zur Abgrenzung von später entstandenen Methoden wie GitOps (siehe unten) wird dieses Vorgehen auch als „CIOps“ bezeichnet. Manchmal wird es dabei als Antipattern dargestellt. Das Verfahren hat sich allerdings jahrelang in der Praxis bewährt und es spricht generell nichts dagegen, es weiterhin zu verwenden.
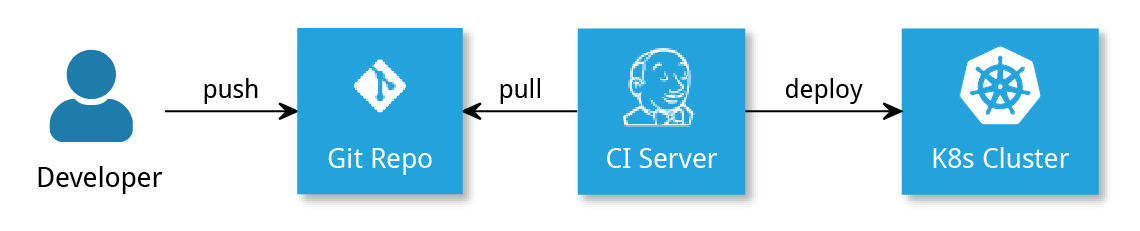 Abbildung 1: Klassische CD-Pipeline (CIOps)
Abbildung 1: Klassische CD-Pipeline (CIOps)
Eine einfach umsetzbare Logik zur Automatisierung des Deployments in einer CIOps-Pipeline mit Staging- und Produktionsumgebungen ist die Verwendung von Branches in Git. Dafür nutzen viele Teams Feature Branches oder Git Flow, in denen der integrierte Entwicklungsstand auf dem Develop-Branch zusammenfließt und der Main- (oder Master-) Branch die produktiven Versionen enthält. Darauf kann einfach eine CD-Strategie aufgebaut werden: Jeder Push auf Develop führt zu einem Deployment auf die Staging-Umgebung, jeder Push auf Main geht in Produktion. So steht stets die letzte integrierte Version auf Staging für funktionale oder manuelle Tests bereit. Durch einen Pull Request (PR) oder Merge auf Main wird dann das Deployment in Produktion angestoßen. Zudem ist ein Deployment pro Feature Branch denkbar.
Der Nachteil dieses Vorgehens ist, dass für jedes Deployment ein Build im CI-Server durchlaufen werden muss. Das macht den Prozess langsamer. Denn generell soll ja dasselbe Artefakt auf allen Stages deployt werden. Es wäre also gar kein neuer Build, Test oder gar Versionsname nötig. Eine solche Deployment-Logik lässt sich mit Jenkins Pipelines einfach realisieren, da der Branch-Name in Multibranch-Builds aus dem Environment abgefragt werden kann. Ein ausführliches Beispiel, das eine vollständige Implementierung mit Jenkins zeigt, ist in diesem Artikel beschrieben, das vollständige Jenkinsfile kann bei GitHub eingesehen werden.
Mittlerweile gibt es im K8s-Umfeld eine Alternative zu CIOps: GitOps. Hier prüft eine im K8s-Cluster laufende, Cloud-native Anwendung (der „GitOps-Operator“) kontinuierlich den tatsächlichen Zustand des Clusters gegen den Wunschzustand, der in einem Git-Repository beschrieben ist. Deployments werden durch einen Push auf dieses Repository, beispielsweise durch die Annahme eines PR, ausgelöst (siehe Abbildung 2). Durch GitOps ergeben sich einige Vorteile:
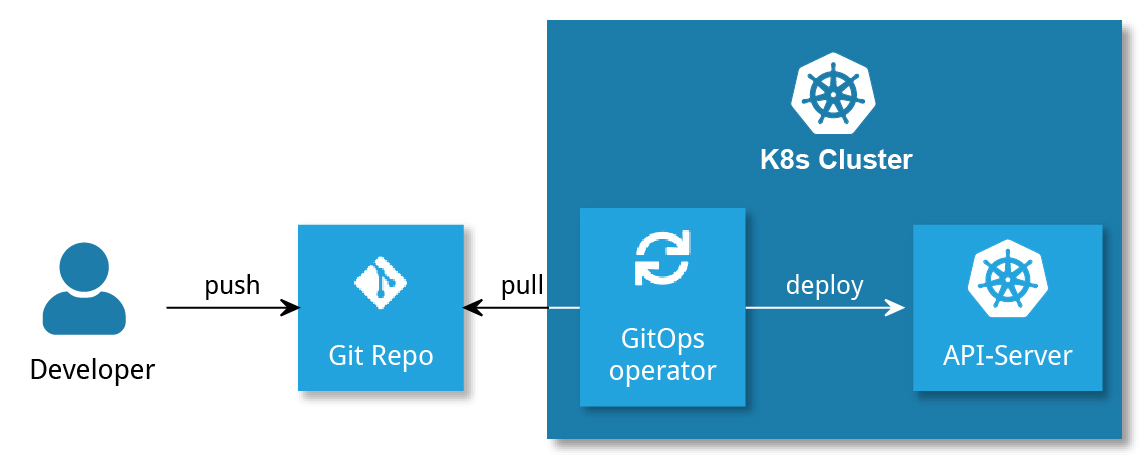 Abbildung 2: Einfaches Deployment mittels GitOps
Abbildung 2: Einfaches Deployment mittels GitOps
Für das Deployment von Third-Party-Anwendungen (die nicht selbst entwickelt werden), ist ein CI-Server nicht mehr unbedingt nötig. Bei selbst geschriebenen Anwendungen sind nach wie vor Build, Tests, etc. auszuführen. Dies übernimmt weiterhin der CI-Server, genauso wie das Pushen des Images in eine Registry (siehe Abbildung 3). Außerdem kann der CI-Server eingesetzt werden, um einige der Herausforderungen von GitOps zu lösen:
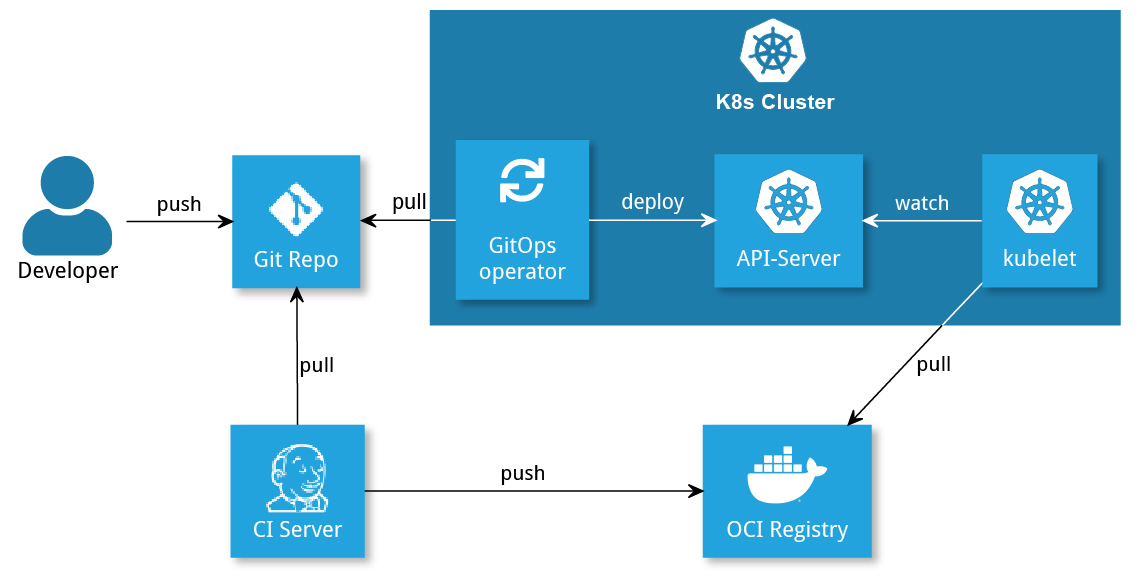 Abbildung 3: GitOps-Deployment von selbst entwickelten Images
Abbildung 3: GitOps-Deployment von selbst entwickelten Images
Durch Unterstützung des CI-Servers kann erreicht werden, dass beides im Repository der Anwendung (im Folgenden als App-Repository bezeichnet) verbleibt. Der CI-Server pusht dann den Infrastruktur-Code in das GitOps-Repository (siehe Abbildung 4).
Lernen Sie alles zur Einführung von GitOps bis hin zur Umsetzung mit Kubernetes in unserer Schulung.
Zur SchulungDie Implementierung eines GitOps-Flows, wie in Abbildung 4 gezeigt, klingt zunächst sehr einfach zu implementieren. Doch wie so oft liegt auch hier der Teufel im Detail: Zum einen warten Herausforderungen bei der Implementierung, zum anderen fallen schnell weitere Punkte auf, die durch die Pipeline automatisiert werden können. So kann am Ende die zunächst einfach erscheinende Implementierung einer solchen Pipeline doch aufwendig werden.
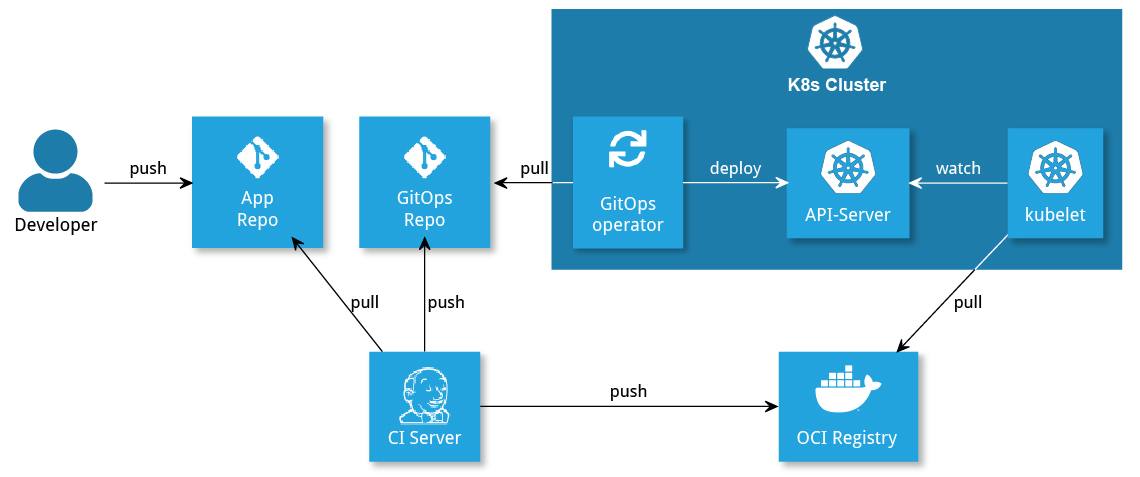 Abbildung 4: Deployment mit App-Repository und GitOps-Repository
Abbildung 4: Deployment mit App-Repository und GitOps-Repository
Die größte Herausforderung ist, dass mehrere gleichzeitige Builds laufen können, die in dasselbe GitOps-Repository schreiben. Eine zuverlässige Fehlerbehandlung solcher Concurrency-Issues führt zu überraschender Komplexität. Wenn die Pipeline dann einmal grundlegend funktioniert, kann der Entwicklungsprozess durch weitere Automatisierung effizienter gestaltet werden. Beispiele für solche Erweiterung folgen später.
Konkrete Beispiele für GitOps-Flows bietet der GitOps-Playground, mit dem in einem lokal ausführbaren Cluster verschiedene GitOps-Operator, wie Flux (GitOps Toolkit) und ArgoCD (GitOps Engine) im Zusammenspiel mit Jenkins ausprobiert werden können.
Darin enthalten ist auch eine Jenkins Pipeline (Vor der Extraktion in die Library; Nach der Extraktion in die Library). Diese ist ähnlich aufgebaut wie das erwähnte CIOps-Beispiel. In zwei Punkten unterscheiden sich die Pipelines jedoch grundlegend:
Die grundlegende Ordnerstruktur des GitOps-Repository zeigt Abbildung 5: Auf oberster Ebene gibt es einen Ordner pro Stage. Darin enthalten ist je ein Ordner pro Applikation. Das Deployment unterscheidet sich dann leicht, je nachdem wie Stages gelöst sind:
 Abbildung 5: Mögliche Ordnerstruktur eines GitOps-Repositories
Abbildung 5: Mögliche Ordnerstruktur eines GitOps-Repositories
Der Ablauf der erwähnten Pipeline aus dem GitOps-Playground ist wie folgt:
Nachdem diese Pipeline durchlaufen ist, wird die Anwendung vom GitOps-Operator zum Review auf Staging deployt. Darüber hinaus existiert ein PR, der bei Annahme direkt (ohne CI-Server) zu einem Deployment in Produktion führt.
Die oben beschrieben Concurrency-Issues können zwischen dem Klonen des Repository und den Pushes auftreten: Wenn zwischenzeitlich das remote Repository geändert wurde, scheitert der Push und damit der Build. Das macht die Entwicklung komplizierter und langsamer. Die Pipeline im Beispiel hat daher einen einfachen Retry-Mechanismus. Scheitert der Push, erfolgt ein Pull und ein erneuter Push. Diese Lösung ist nicht perfekt, da bei Konflikten der Build trotzdem scheitert. Unter gewissen Umständen kann sogar eine Inkonsistenz entstehen: Beim Pull könnte ein Fast Forward Merge gemacht werden, der die Änderungen aus dem Build mit denen aus einem anderen „vermischt“. Hier wäre es also sicherer, nach dem Pull nicht einfach zu pushen, sondern einen Reset auf den Remote-Stand zu machen und die Änderungen erneut durchzuführen.
An anderer Stelle zeigt sich die Pipeline schon recht ausgefeilt. So werden die Commits, die der Job am GitOps-Repository vorgenommen hat, für mehr Transparenz in der Jenkins Job Description angezeigt. Für ein effizienteres Review des PR wird Folgendes in die Commit Message im GitOps-Repository geschrieben (Abbildung 6 zeigt dies am Beispiel mit SCM-Manager):
 Abbildung 6: Beispiel eines vom CI-Server erstellten Commits im GitOps-Repository
Abbildung 6: Beispiel eines vom CI-Server erstellten Commits im GitOps-Repository
Derzeit sind im GitOps-Playground noch weitere Features in Arbeit, die den Prozess effizienter gestalten. Möglicherweise sind diese zum Zeitpunkt der Veröffentlichung des Artikels schon verfügbar:
yamlint. Ein weiterer Schritt ist das Prüfen der K8s-Ressourcen gegen das K8s-Schema. Dies kann mit dem Tool kubeval erfolgen. Bei Helm-Charts mit eigenem Schema könnte auch gegen dieses geprüft werden (mittels helm lint)Die vorgestellten Beispiele zu CIOps und GitOps zeigen, wie einfache K8s-Ressourcen auf den Cluster mit der jeweiligen Methode angewendet werden können. Nachteil dabei ist, dass die K8s-Ressourcen komplett redundant für jede Stage gespeichert werden müssen. In der Praxis werden daher oft Templating-Tools eingesetzt, die eine Parametrisierung einer einzigen Quelle (ohne Redundanz) ermöglichen. Helm, der offizielle Package Manager für K8s, ist eine gängige Lösung. Mit Helm können nicht nur Third-Party-Packages deployt werden. Seine Templating-Funktion kann auch für die lokale Entwicklung genutzt werden.
Für die lokale Entwicklung gibt es einige Alternativen zu Helm, wie das „Template-freie“ Tool Kustomize, das mit sogenannten Overlays arbeitet, die mit dem Patch-Mechanismus auf eine Basisdatei angewendet werden.
Bei CIOps lassen sich Templating-Tools relativ einfach anwenden. Die Tools stehen als Kommandozeilenwerkzeug zur Verfügung, das in der Pipeline aufrufbar ist. Ein Beispiel dafür steht bei GitHub zur Verfügung. Hier wird das Helm-Binary als Container ausgeführt, sodass keine weitere Konfiguration seitens des Jenkins-Controller erforderlich ist. Einige weitere wertvolle Erkenntnisse aus der Praxis:
helm upgrade --install muss nicht aufwendig zwischen Erstinstallation und Upgrade unterschieden werdenvalues.yaml beschreibt Standardwerte, eine weitere values-Datei pro Stage setzt die jeweils spezifischen Werte. Diese Datei muss dem Helm-Befehl per –-values-Parameter übergeben werden, die Standard values.yaml wird implizit immer angezogen--set 'image.tag=...Bei der Verwendung von Templating-Tools mit GitOps wartet zu Beginn eine große Herausforderung: Wie kann der imperative Aufruf (beispielsweise helm upgrade) in eine deklarative Form gebracht werden, die im GitOps-Repository abgelegt werden kann? Die Lösung: weitere Operatoren in K8s. Für die weit verbreiteten Tools Helm und Kustomize existieren solche Operatoren bereits, für anderen Templating-Tools nicht unbedingt. Auch hier gibt es ein Praxisbeispiel im GitOps-Playground (Vor der Extraktion in die Library; Nach der Extraktion in die Library). Darin wird eine statische HTML-Seite mit dem Webserver NGINX ausgeliefert. Dieses Beispiel käme auch ohne Pipeline aus, allerdings mit den oben erwähnten Nachteilen:
Insofern ist an dieser Stelle die Verwendung einer Pipeline auch beim GitOps-Deployment von Third-Party-Anwendungen vorteilhaft. Beim Blick auf die beiden Jenkinsfiles aus dem GitOps-Playground fällt auf, dass die Pipelines für die beiden unterschiedlichen Anwendungsfälle „K8s-Ressourcen“ und Helm zu großen Teilen gleich sind. Hier ermöglicht das Auslagern in eine Jenkins Shared Library Wiederverwendung und besser wartbare Pipelines. Dies führte zur Entwicklung der GitOps-Build-Lib, in der die in diesem Artikel beschriebenen Pipeline logike nun zu Hause sind.
Abschließend sei angemerkt, dass die Nutzung eines Helm-Operators auch ohne GitOps Vorteile haben kann: Die Quelle und Version des Charts sind als IaC (in YAML) deklariert, statt innerhalb eines Jenkinsfiles. Dieses wird einfach auf den Cluster angewendet. In der Pipeline wird kein Helm Binary mehr benötigt. Das gleiche Vorgehen funktioniert auch in der lokalen Entwicklung.
Die Mehrwerte von CD stehen außer Frage. Dieser Artikel zeigt anhand beispielhafter CD-Implementierungen mit K8s- und Helm-Deployment, dass die Realisierung sowohl mit CIOps als auch GitOps gut mit Jenkins möglich ist. Die Frage „CIOps oder GitOps“ ist also ein Implementierungsdetail. Beides kann hervorragend in der Praxis funktionieren. Wer bereits bestehende CD-Prozesse hat, sollte nur umstellen, wenn die Vorteile von GitOps im jeweiligen Anwendungsfall große Mehrwerte bringen. Nicht zu unterschätzen ist dabei der Aufwand für die Migration: Wer viele Pipelines hat, muss auch viele Pipelines migrieren. Für Neueinsteiger bietet es sich aufgrund der vielen Vorteile an, direkt mit GitOps zu starten. Allerdings wird die bereits steile Lernkurve dadurch noch steiler. Die vollständigen Beispiele können bei GitHub in den Repositories für CIOps und GitOps gefunden werden. Was dieser Artikel nicht betrachtet, sind die Unterschiede verschiedener GitOps-Operatoren. Dies ist ein Thema für sich. Ein erster Schritt, sich diesem praktisch zu nähern, kann der GitOps-Playground oder unser Post über GitOps-Werkzeuge sein, der auch Flux and ArgoCD vergleicht.



