
: Phases and Processes")

02/23/2021
in EcoSystem
DevOps Basics (2/2): Phases and Processes
Table of Contents
This article is part 2 of the series „DevOps Basics“
Read the first part now.
As you already learned in our last post, DevOps combines previously assigned tasks and roles at a company on the basis of agile working methods, automation, and cross-functional cooperation in order to create a common basis for value creation. This means that tasks that were previously assigned to development and operating teams are now assigned to a core team where they can be repeatedly performed over and over again. We can therefore speak of a so-called “DevOps life cycle”.
What phases does a project go through with DevOps?
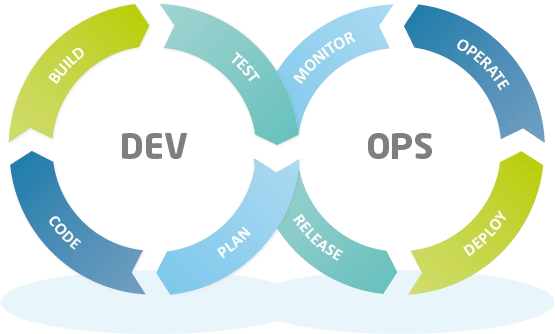
The phases that make up this cycle are often given various names depending on who you are talking to, but in the end they always have the same goal: to divide the overall process into smaller parts and phases to make planning and implementation easier to understand. It should be mentioned here, however, that DevOps is a closed, continuously performed process and that the phases that are described here flow into one another.
Plan
The planning phase includes everything that happens before the actual development of the program code. The focus here is on a road map that is used to plan the implementation of changes to the product. These changes can be based on both user feedback as well as on in-house requirements. In a modern tool that is used to map the DevOps pipeline, these artifacts are then converted into epics, features, and user stories. In preparation of the next phase, sprints are then planned from these based on derived tasks. Tools for planning tasks include, for example, JIRA, Redmine, or EasyRedmine.
Code
Once the tasks are assigned, the development teams get to work and write the actual program code. Progress is communicated to the team at regular meetings (stand-ups and sprint reviews). In order to ensure that all development teams are on the same page, a common framework of tools and plug-ins as well as uniform specifications for code quality are agreed upon. In addition to an IDE for writing the code, a tool for source code management, such as SCM-Manager, is required during this phase. In addition, wikis such as Confluence or Smeagol can also help you document the code.
SCM-Manager
The easiest way to share and manage your Git, Mercurial and Subversion repositories.
Getting startedBuild
As soon as a task is completed, the code is transferred to a central repository. This so-called “push” triggers a so-called “pull request”, which is used to perform a code review. Then the pull request is confirmed if everything is OK. At the same time, automated tests are already performed that check the new code for possible bugs. If one of these tests fails, information is sent immediately and the code can be improved. If all tests are passed, the new code is adopted. A build server, such as Jenkins, is essential in this phase.
Test
In addition to the test procedures that are already conducted during the build phase, more in-depth tests can be performed in a separate environment which is additionally used for deployment. This environment is often referred to as the “staging environment”. In this environment, manual tests can also be conducted in addition to in-depth, automated tests. The former may include, for example, integration and security tests to uncover any weak points in the application. In addition, user acceptance tests can be carried out in the staging environment before publication. Tests can be conducted using SonarQube or Sonatype Lifecycle, for example.
Release
After these extensive and in-depth testing procedures have been completed, measures to prepare for publication in a production environment can be performed. At this point, it is decided which changes should be included in the release. Depending on the maturity of the release process, this can be a manual or an automatic step. Some companies publish new versions on a fixed schedule, while others do this automatically as soon as new code has successfully passed the test phase. Dedicated persons may be assigned the role of release manager. Artifact repository management tools, such as Nexus Repository, can be used to manage versions and releases.
Deploy
This is the phase in which the new build is actually rolled out. Thanks to modern tools, this is now automated and can be performed without interrupting regular operations. The same code that was already used for deployment in the test environment can be used here – Keyword: Infrastructure-as-a-Code. Should unexpected difficulties arise during the deployment phase, the previous state of the production environment can be temporarily restored without any problems. Automated deployment may be conducted with Jenkins, for example.
Operate
The changes are now live and available to users. During this phase, the part of the team that primarily deals with operations plays a role.
Modern tools automatically ensure that peak loads are effectively absorbed and that the necessary resources are made available at all times to operate the production environment effectively. In addition, the customer has the opportunity to give feedback to the team. This is the only way to gain valuable insights into how the software is used and what the users want. This is one of the greatest success factors and must be guaranteed!
Monitor
In addition to the direct feedback from users, further data that is generated during use should also be collected. These may include, for example, bugs, latency times, access numbers, and the individual usage behavior of users. The mixture of direct customer feedback and the additional collected data can then flow back to the product managers and development teams so that they can derive future features from them. In this way, users can have what they really want and need developed.
Continuous … everything!
Since, as we mentioned at the beginning, these phases represent an ongoing process, in the DevOps area you will often come across such keywords as continuous integration, continuous delivery, and continuous deployment, which are generally abbreviated as CI/CD. Let’s take a closer look at what these terms mean and how they fit into the phases mentioned above.
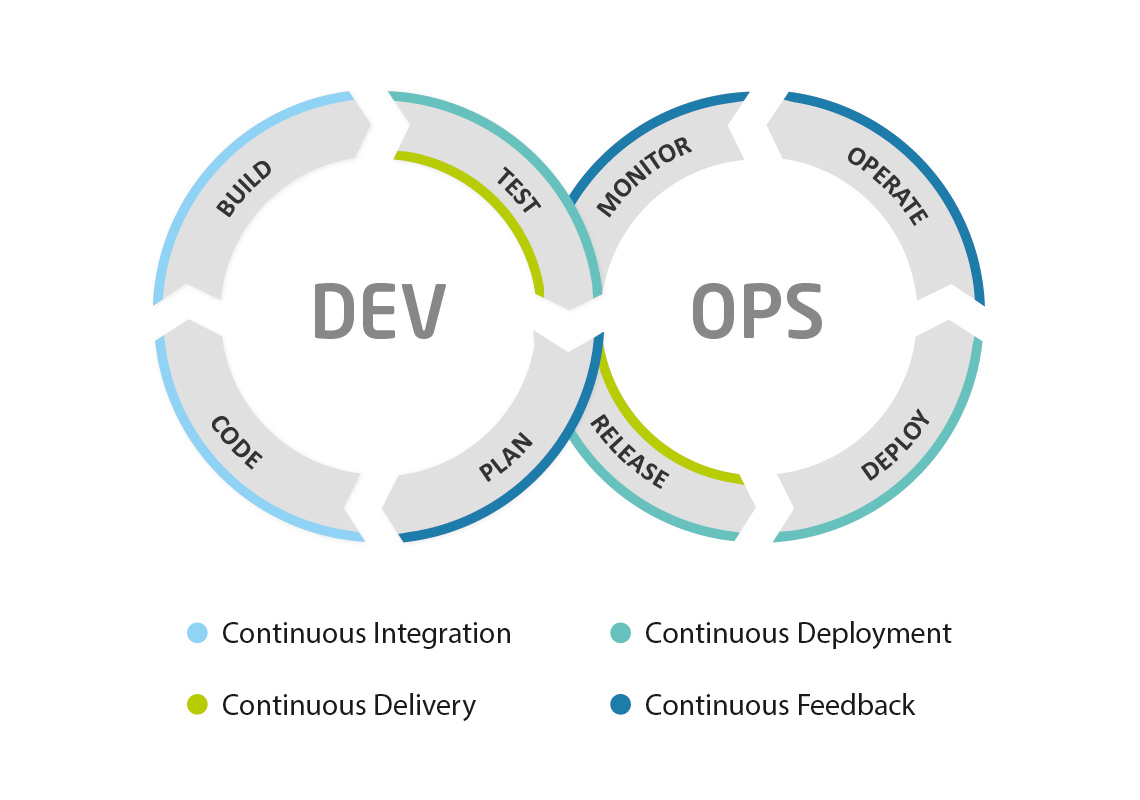
Continuous integration
At its core, continuous integration means that code changes are frequently and regularly integrated into a common repository. This may not sound revolutionary, but it forms an indispensable basis for all the procedures, principles, and steps of a DevOps approach.
The more frequent incorporation of these smaller software modules ensures that regular tests can be carried out, reduces the complexity of the individual modules, and allows errors/compatibility problems to be fixed more easily and quickly. This means that less debugging is required. In addition, the changes implemented by the team are made more visible and a sustainable, solid basis for all upcoming changes is laid.
Automated tests already play a major role here, which reduces the amount of required manual testing. Apparently, more bugs can be found due to the more frequent integration of the software modules, but these are much easier to fix because the program modules are smaller and less complex.
In the end, this approach should produce an easier and repeatable process that automatically detects bugs, cuts costs, and makes the entire software cycle more efficient.
Continuous delivery and continuous deployment
If this approach is further automated and expanded on the basis of continuous integration, it is called continuous delivery. This means that the software can therefore be continuously delivered, i.e., deployed from the code base.
If the code successfully passes through all test phases (unit/integration/system tests) and has been successfully deployed in the staging environment, a manual release can be performed in the production customer environment, ideally at the push of a button.
If the release process for deployment to the production environment is also automated, it is referred to as continuous deployment. If manual steps are still necessary here, we can speak of continuous delivery.
Continuous deployment is therefore the ultimate goal of modern software development, and it always takes the path of step-by-step implementation and the development of continuous integration and continuous delivery.
Continuous feedback
The last core element can be understood as a fundamental goal in order to obtain continuous feedback from the market and users. Ultimately, the goal of DevOps is to get the software into the hands of the users more quickly in order to receive direct feedback on how the new features are being adopted.
This feedback then flows back into the development process and thus significantly influences the further course of action by the team. This creates an effective feedback loop that can and should provide important guidance for the alignment and design of your software products.
Feedback not only includes customer voices, such as, for example, via communities and direct feedback from users, but also the automated metrics that a modern DevOps pipeline can provide to you. For example, if you deliver an update and your monitoring tool reports that the CPU and memory usage of the production server has risen in critical areas since delivery, this is also an important piece of feedback that influences how your team should proceed.

A modern DevOps toolchain supports all these concepts, phases, and procedures with suitable tools that can make software development based on the DevOps principle considerably easier. We have developed the Cloudogu EcoSystem for this purpose—you don’t have to do extensive research or spend days on configuration work. Thanks to our ecosystem, you can configure your own CI/CD toolchain in just 30 minutes. Please get in touch with us!
This article is part 2 of the series „DevOps Basics“.
Read all articles now:


