


13.07.2018
in Technology
Coding Continuous Delivery — Statische Code Analyse mit SonarQube und Deployment auf Kubernetes et al. mit dem Jenkins Pipeline Plugin
Inhaltsverzeichnis
+++ Der Originalartikel kann hier heruntergeladen werden: Zeitschriftenartikel, veröffentlicht in Java aktuell 04/2018.+++
Die ersten drei Teile dieser Artikelserie zum Thema Jenkins Pipelines beschreiben Grundlagen, Performance und Werkzeuge wie Shared Libraries und Docker©. Dieser letzte Teil widmet sich der Integration statischer Code Analyse mittels SonarQube. Zum Abschluss der Artikelserie zeigt er wie man kontinuierlich auf Kubernetes ausliefern kann und gibt Anregungen für Continuous Delivery (CD) auf anderen Plattformen.
Die Pipeline-Beispiele aus den Vorgängern werden in diesem Artikel sukzessive erweitert. Das Beispielprojekt ist weiter der kitchensink Quickstart von WildFly. Alle Pipeline-Beispiele werden sowohl in declarative als auch scripted Syntax realisiert. Den aktuellen Stand jeder Erweiterung kann man bei GitHub nachverfolgen und ausprobieren. Hier gibt es für jeden Abschnitt unter der in der Überschrift genannten Nummer jeweils für declarative und scripted einen Branch, der das vollständige Beispiel umfasst. Das Ergebnis der Builds jedes Branches lässt sich außerdem direkt auf unserer Jenkins-Instanz einsehen. Die Nummerierung der Branches setzt sich damit aus den vorhergehenden Teilen fort. Docker© war Nummer neun, also ist die statische Code Analyse das zehnte Beispiel.
Statische Code Analyse mit SonarQube (10)
Statische Code Analyse erfasst gängige Fehlermuster, Code Style und Metriken (z.B. Code Coverage) anhand des Source- oder Bytecodes. Auf Basis der Metriken können dann Quality Goals festgelegt werden, z.B. „Code Coverage muss bei neuem Code größer 80% sein“.
Diese Schritte sind gut automatisierbar und sind deshalb ein weiteres Mittel zur Qualitätssicherung in einer CD-Pipeline, neben den bereits gezeigten Unit- und Integrationstests. Weit verbreitet ist dabei das Werkzeug SonarQube (SQ), das in einer eigenen Webanwendung gekapselt die Möglichkeit zur statischen Code Analyse bietet. Dabei können über Plugins viele Programmiersprachen und die Regeln von Tools wie FindBugs, PMD und Checkstyle integriert werden.
Die Integration in die Jenkins Pipeline erfolgt per Jenkins Plugin. Nach der Installation wird in Jenkins die SQ-Instanz konfiguriert, typischerweise mittels URL und Authentication Token.
In SQ wird zudem ein Webhook eingerichtet, der Jenkins über die Ergebnisse der Quality Gate Checks asynchron informiert. Der Webhook wird vom SQ-Plugin auf Jenkins bereitgestellt sonarqube-webhook.
Die Analyse kann man dann unter anderem vom SQ-Plugin für Maven auf Jenkins durchführen lassen. Listing 1 zeigt wie das mit scripted Syntax in der Jenkins Pipeline abgebildet werden kann.
node {
stage('Statical Code Analysis') {
analyzeWithSonarQubeAndWaitForQualityGoal()
}
}
// ...
void analyzeWithSonarQubeAndWaitForQualityGoal() {
withSonarQubeEnv('sonarcloud.io') {
mvn ‘${SONAR_MAVEN_GOAL} -Dsonar.host.url=${SONAR_HOST_URL} -Dsonar.login=${SONAR_AUTH_TOKEN} ${SONAR_EXTRA_PROPS} ‘
}
timeout(time: 2, unit: 'MINUTES') {
def qg = waitForQualityGate()
if (qg.status != 'OK') {
currentBuild.result = 'UNSTABLE'
}
}
}
Listing 1
Das SQ-Plugin stellt auf der Pipeline verschiedene Steps bereit:
withSonarQubeEnv()injiziert die in der Konfiguration für eine SQ-Instanz (hier mit der IDsonarcloud.io) angegebenen Werte wie die URL als Environment Variablen in den entsprechenden Block.waitForQualityGate()wartet auf den Aufruf des Webhooks, der über den Zustand des Quality Gates informiert.
In Listing 1 wird bei negativem Ergebnis der Build auf unstable (yellow) gesetzt. Hier ist alternativ auch ein Aufruf des error() Steps möglich, der den Build auf failed (rot) setzt.
Um zu verhindern, dass der Build hier unbegrenzt wartet, wird eine Timeout gesetzt. Ist z.B. kein Webhook konfiguriert, wird der Build nach 2 Minuten abgebrochen.
Auch hier empfiehlt es sich, die Logik in einen eigenen Step analyzeWithSonarQubeAndWaitForQualityGoal() auszulagern, um den Pipeline Code lesbarer zu gestalten. In declarative Syntax muss mindestens die Prüfung des Quality Gates in einen eigenen Step oder script-Block geschrieben werden.
In der offiziellen Pipeline Doku wird zwar empfohlen, den Step waitForQualityGate() außerhalb eines Node durchzuführen, um diesen so wenig wie möglich zu blockieren. Dies führt allerdings zu schwerer wartbarem Code. Siehe dazu die Beispiele bei GitHub im Branch 10a, jeweils für scripted and declarative. In declarative Syntax führt dies unter anderem dazu, dass jede Stage in einem eigenen Build Executor ausgeführt wird, wodurch sich zudem die Gesamtlaufzeit der Pipeline deutlich verlängert. Da die Antwortzeiten von SQ typischerweise bei wenigen Millisekunden liegen, zeigt Listing 1 den pragmatischen Weg innerhalb des Nodes.
Es gibt noch einige fortgeschrittene Themen im Umgang mit SQ, z.B. die Ergebnisse der Analyse direkt als Kommentar in Pull Requests schreiben zu lassen oder die Verwendung des Branch-Feature (nicht in der Community Edition). Diese Features werden z.B. von der Shared Library ces-build-lib komfortabel bereitgestellt.
Deployment (11)
Wenn alle qualitätssichernden Maßnahmen erfolgreich waren, kann zum Abschluss der CD-Pipeline das Deployment erfolgen. Je nach Grad der Automatisierung steht hier am Ende das Deployment in Produktion. Um Risiken beim Deployment in Produktion zu verringern, ist es empfehlenswert mindestens eine Staging-Umgebung zu betreiben. Eine einfach umsetzbare Logik, um sowohl Staging als auch Produktion automatisiert zu deployen, ist die Verwendung von Branches im Source Code Management (SCM).
Viele Teams arbeiten mit Feature Branches oder Git Flow, in denen der integrierte Entwicklungsstand auf dem Develop Branch zusammenfließt und der Master Branch die produktiven Versionen enthält. Darauf kann man einfach seine CD-Strategie aufbauen: Jeder Push auf Develop führt zu einem Deployment auf die Staging-Umgebung, jeder push auf Master geht in Produktion. So hat man stets die letzte integrierte Version auf Staging und kann dort funktionale oder manuelle Tests durchführen, bevor man durch einen Merge auf Master das Deployment in Produktion anstößt. Zudem ist ein Deployment pro Feature Branch denkbar.
Eine solche Deployment-Logik lässt sich mit Jenkins Pipelines einfach realisieren, da man den Branch-Namen in Multibranch Builds aus dem Environment abfragen kann (siehe Listing 2, Stage deploy).
Wohin und wie man Software deployed hängt vom Projekt ab. In den letzten Jahren haben sich Container Orchestration Platforms als flexibles Mittel für DevOps-Teams erwiesen. Hier hat sich Kubernetes (K8s) als defacto Standard herauskristallisiert, weshalb dieser Artikel exemplarisch das Deployment auf K8s beschreibt. Um eine Anwendung auf K8s zu deployen, sind vier Schritte notwendig:
- Versionsnamen festlegen
- Docker© Image bereitstellen (Image bauen, mit Version als Tag und in Registry hochladen),
- Image Version in Deployment-Beschreibung (typischerweise in YAML) aktualisieren,
- YAML Datei auf K8s Cluster anwenden.
Listing 2 zeigt die Umsetzung dieser Schritte in scripted Syntax.
node {
String versionName = createVersion()
stage('Build') {
mvn ‘clean install -DskipTests -Drevision=${versionName}’
}
// ...
stage('Deploy') {
if (currentBuild.currentResult == 'SUCCESS') {
if (env.BRANCH_NAME == ‘master’) {
deployToKubernetes(versionName, 'kubeconfig-prod', 'hostname.com')
} else if (env.BRANCH_NAME == 'develop') {
deployToKubernetes(versionName, 'kubeconfig-staging', 'staging-hostname.com')
}
}
}
}
String createVersion() {
String versionName = ‘${new Date().format('yyyyMMddHHmm')}’
if (env.BRANCH_NAME != ‘master’) {
versionName += '-SNAPSHOT'
}
currentBuild.description = versionName
return versionName
}
void deployToKubernetes(String versionName, String credentialsId, String hostname) {
String DockerRegistry = 'your.Docker.registry.com'
String imageName = “${DockerRegistry}/kitchensink:${versionName}"
Docker.withRegistry("https://${DockerRegistry}", 'Docker-reg-credentials') {
Docker.build(imageName, '.').push()
}
withCredentials([file(credentialsId: credentialsId, variable: 'kubeconfig')]) {
withEnv(["IMAGE_NAME=${imageName}"]) {
kubernetesDeploy(
credentialsType: 'KubeConfig',
kubeConfig: [path: kubeconfig],
configs: 'k8s/deployment.yaml',
enableConfigSubstitution: true
)
}
}
timeout(time: 2, unit: 'MINUTES') {
waitUntil {
sleep(time: 10, unit: 'SECONDS')
isVersionDeployed(versionName, "http://${hostname}/rest/version")
}
}
}
boolean isVersionDeployed(String expectedVersion, String versionEndpoint) {
def deployedVersion = sh(returnStdout: true, script: "curl -s ${versionEndpoint}").trim()
return expectedVersion == deployedVersion
}
Listing 2
Der Versionsname lässt sich mit Hilfe von Groovy erzeugen, z.B. als Zeitstempel in Listing 2. Hier könnte man durch Anhängen des Git Commit Hashs mehr Eindeutigkeit schaffen. Denkbare wäre es außerdem aus der Pipeline einen Git Tag zu setzen.
Um diese Version auch in Maven zu verwenden, bietet sich die Nutzung der ab Maven 3.5.0 verfügbaren CI Friendly Versions an. Wie dies in der pom.xml umgesetzt wird, zeigt Listing 3.
<project>
<version>${version}</version>
<properties>
<version>-SNAPSHOT</version>
</properties>
</project>
Listing 3
Im Build wird die Version dann mittels des Arguments -Drevision (siehe Listing 2) an Maven übergeben.
Die weiteren Schritte in Listing 2 sind in einem eigenen Step deployToKubernetes() realisiert. Dieser wird jedoch erst nach der Prüfung, ob der Build noch stabil ist aufgerufen. Wenn z.B. das Quality Gate fehl schlug, soll natürlich nicht deployed werden.
Das Bauen und Hochladen des Images lässt sich dank der im letzten Teil beschriebenen Docker©-Integration leicht mit Jenkins-Bordmitteln realisieren. Dabei muss man sich bei der Docker© Registry authentifizieren. Dafür hinterlegt man in Jenkins Username and Password Credentials an (Docker-reg-credentials in Listing 2). Deren Herkunft hängen vom Anbieter der Registry ab, beispielsweise ist das Password bei der Google Container Registry eine JSON-Datei, die man in einfachen Anführungszeichen ohne Zeilenumbrüche in Jenkins einfügt.
Um den Versionsnamen in die YAML-Datei zu schreiben, kann man einen eigenen Step zum Ersetzen im Jenkinsfile schreiben oder man verwendet ein Plugin.
Eine komfortable Möglichkeit ist das kubernetes-cd-plugin. Es stellt den Step kubernetesDeploy () zur Verfügung, der YAML-Dateien filtert und direkt auf den Cluster anwendet.
Dabei werden alle Einträge mit der $VARIABLE Syntax in den YAML-Dateien durch entsprechende Environment Variablen aus der Jenkins Pipeline ersetzt (in Listing 2, z.B. IMAGE_NAME).
Um die YAML Datei auf den Cluster anwenden zu können, muss sich das Plugin beim K8s-Master authentifizieren. Dafür erzeugt man einen K8s Service Account für Jenkins und legt dessen Rechte mittels Role-Based Access Control fest. Listing 4 zeigt exemplarisch, wie man imperativ einen Service Account auf einen K8s-Namespace einschränkt. Für die deklarative Variante (in YAML) siehe https://github.com/cloudogu/jenkinsfiles.
kubectl create namespace jenkins-ns
kubectl create serviceaccount jenkins-sa --namespace=jenkins-ns
kubectl create rolebinding jenkins-ns-admin --clusterrole=admin --namespace=jenkins-ns --serviceaccount=jenkins-ns:jenkins-sa
./create-kubeconfig jenkins-sa --namespace=jenkins-ns > kubeconfig
Listing 4
Mit diesem Service Account kann man über die K8s HTTP API, kubectl oder kubernetes-cd-plugin auf den Cluster zugreifen. An das Plugin übergibt man den Service Account als kubeconfig-Datei. Diese lässt sich mit einem Script von GitHub erstellen, wie die letzte Zeile in Listing 4 zeigt. Die durch das Script erstellte Datei kubeconfig lädt man in Jenkins in ein Secret File Credential hoch, z.B. mit der ID kubeconfig-prod (siehe Listing 2). Wenn man Staging-Umgebungen in einem anderen Namespace hat, würde man an dieser Stelle weitere kubeconfig-Dateien für diese erstellen (z.B. kubeconfig-staging in Listing 2).
Da das Anwenden der Datei auf den Cluster bei K8s nur das server-seitige Deployment anstößt, ist danach noch nicht klar, ob die dieses erfolgreich war. Deshalb wird in Listing 2 abschließend geprüft, ob die neue Version erreichbar ist. Dazu muss die Anwendung den Versionsamen bereitstellen. Wie man dies mittels Maven und REST erledigt, zeigt z.B. dieser Blogpost. In Listing 2 ist zu sehen, wie man den Versionsnamen abfragt und vergleicht, ob die Version mit der gewünschten übereinstimmt. Taucht sie nach einer bestimmten Zeit nicht auf, schlägt der Build fehl und die Entwickler werden von Jenkins informiert. In einem solchen Fall zahlt sich die Verwendung von K8s aus: Durch dessen Rolling Update Strategie bleibt die Anwendung weiterhin eingeschränkt verfügbar. In Listing 2 ist der Hostname hart codiert. Alternativ kann man die externe IP-Adresse des Services mittels kubectl abfragen, siehe https://github.com/cloudogu/jenkinsfiles.
Die Umsetzung des Deployments in declarative Syntax erfolgt wie in Listing 2, bis auf folgende Ausnahmen:
createVersion()muss in einemstepsBlock (z.B. innerhalb derbuild-Stage) aufgerufen werden und schreibt sein Ergebnis nachenv.versionName, da keine Variablen imstepsBlock möglich sind.- Die Prüfung, ob der Build noch stabil ist, kann in einer
when-Directive erfolgen (siehe 2. Teil dieser Serie). - Die Prüfung des Branches in der
Deploy-Stage muss innerhalb einesstepsundscriptBlock oder einem eigenen Step stattfinden. Das komplette Beispiel findet man bei GitHub.
Selbstverständlich kann man aus Jenkins Pipelines nicht nur auf K8s deployen. Beispielsweise ist das Deployment auf die Container Orchestration Platform Docker© Swarm dank des eingebauten Docker© Support einfach. Docker© selbst kann man außerdem nutzen, um einfache Staging-Umgebungen aufzubauen, indem man einen Rechner mit Docker© Host als Jenkins Worker einbindet und darauf aus der Pipeline die Container des Staging Systems startet. Auch Deployments auf PaaS-Plattformen ist möglich, z.B. gibt es für CloudFoundry ein Plugin mit Pipeline Unterstützung.
Außer Webanwendungen kann man auch andere Arten von Anwendungen kontinuierlich ausliefern. Zum Abschluss einige Anregungen aus der Praxis:
- Java-Libraries lassen sich mit wenigen Zeilen Pipeline Code nach Maven Central deployen. Ein Beispiel ist der test-data-loader, der die Shared Library ces-build-lib verwendet.
- Docs as code
- In einer Markup-Sprache verfasste und im SCM gespeicherte Dokumentation kann automatisiert in ein fertiges Dokument überführt werden. Dieses Beispiel zeigt wie man aus Markdown mittels Pandoc verschiedene Dokumentenformate wie PDF oder ODT erzeugt. Über Pandocs Template-Mechanismus können die Dokumente im Corporate Design gerendert werden. In diesem Beispiel wird das Build-Tool Gulp verwendet, damit man den Build auch lokal durchführen kann. Im Jenkinsfile wird die für Gulp notwendige Umgebung (node.js, yarn) in einem yarn-Container bereitgestellt. Darin nutzt Gulp den cloudogu/pandoc container zur Dokumentenerstellung. Daher ergibt sich hier die im letzten Teil beschriebene
Docker in Docker-Herausforderung. Um weitere Container aus dem yarn-Container zu starten, wird der Docker© Socket durchgereicht und der Docker©-Client installiert. Auch dies kann in wenigen Zeilen mittels ces-build-lib gelöst werden. Wenn man das Markup in einem Git-basierten Wiki wie Gollum oder Smeagol editiert, wird direkt bei Speicherung im Wiki durch die CD-Pipeline ein PDF ausgeliefert. Dadurch wird Docs as Code für nicht-Entwickler besser zugänglich. - Das funktioniert auch für Präsentationen. Dieses Beispiel zeigt wie man in Markdown Präsentationen mit
reveal.jserstellen und in einer Maven Site (Nexus Repository) oder per Kubernetes (NGINX-Container) im Web bereitstellen kann.
- In einer Markup-Sprache verfasste und im SCM gespeicherte Dokumentation kann automatisiert in ein fertiges Dokument überführt werden. Dieses Beispiel zeigt wie man aus Markdown mittels Pandoc verschiedene Dokumentenformate wie PDF oder ODT erzeugt. Über Pandocs Template-Mechanismus können die Dokumente im Corporate Design gerendert werden. In diesem Beispiel wird das Build-Tool Gulp verwendet, damit man den Build auch lokal durchführen kann. Im Jenkinsfile wird die für Gulp notwendige Umgebung (node.js, yarn) in einem yarn-Container bereitgestellt. Darin nutzt Gulp den cloudogu/pandoc container zur Dokumentenerstellung. Daher ergibt sich hier die im letzten Teil beschriebene
- Infrastruktur as code: Even entire virtual machines can be provisioned in the cloud, e.g., using the Terraform tool.
Individuelle Beratung für Sie
Schaffen Sie mit uns den optimalen Rahmen für erstklassige Softwareentwicklung in Ihrem Unternehmen.
Zum GitOps ConsultingZusammenfassung und Ausblick
Diese Artikelserie zeigt einige der Möglichkeiten die das Jenkins Pipeline Plugin bietet. Es kombiniert die bereits vorhandene große Auswahl an Jenkins Plugins mit einer DSL zur Beschreibung von Build Jobs. So kann man Builds Jobs als Code formulieren. Diese sind schneller verständlich, können im SCM verwaltet, einfacher wiederverwendet (beispielsweise mittels Shared Libraries) und automatisch getestet werden. Durch Parallelisierung kann man außerdem vorhandene Ressourcen nutzen, um mit geringem Aufwand die Laufzeiten der Pipelines zu verkürzen. Die Docker©-Integration ermöglicht ohne weitere Konfiguration die Benutzung von weiteren Werkzeugen und die Möglichkeit Images während des Deployments in eine Registry bereitzustellen.
Ob man Pipelines in scripted oder declarative Syntax beschreibt bleibt Geschmackssache. Beim Schreiben der Beispiele für den Artikel auf, dass gerade bei komplexeren Aufgaben die declarative Lösung oft umständlicher, aber generell machbar war. Vorteil von declarative Pipelines ist, dass sie besser in das Blue Ocean-Theme integriert sind und dort visuell editiert werden können.
Die finale Pipeline (siehe Abbildung 1) umfasst in beiden Varianten ungefähr 150 Zeilen. Dabei entspricht sie von der Komplexität durchaus der eines „echten“ Projekts.
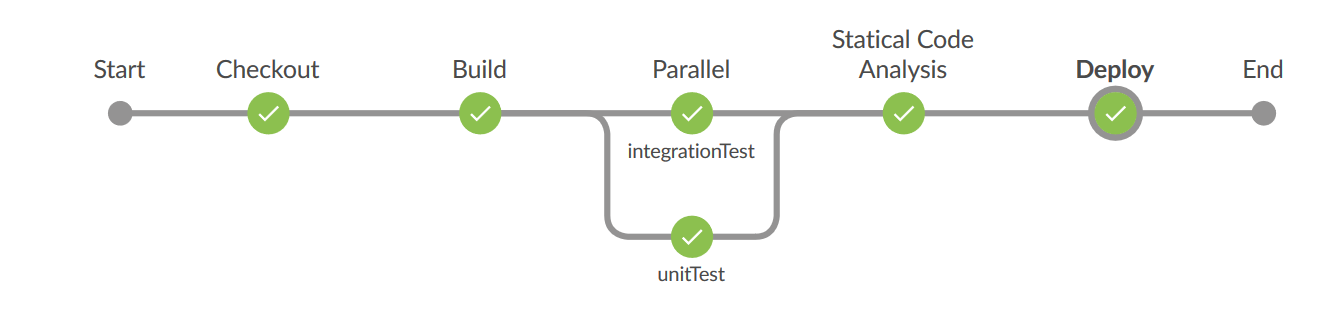
An wenigen Stellen (z.B. Nightly Builds, Möglichkeiten für Unit und Integrationstest der Pipeline) zeigt sich zwar, dass noch nicht alles perfekt ist. Dennoch ist das Pipeline Plugin die wichtigste Neuerung der letzten Jahre für Jenkins und sorgt dafür, dass wir den altgedienten Butler auch weiterhin für moderne Softwareentwicklung einsetzen können.


