


05/02/2018
in Technology
Coding Continuous Delivery — Performance optimization for the Jenkins Pipeline
Table of Contents
This article is part 2 of the series „Jenkins Pipeline for continuous delivery“
Read the first part now.
After the first part of this article series (see part 1), describes the basic terms and a first Jenkins Pipeline, this part shows how you can get faster feedback by accelerating pipelines using parallelization and nightly builds.
In the following, the pipeline examples from the first article will be successively expanded to demonstrate the features of the Pipeline. In so doing, the changes will be presented in both declarative and scripted syntax. The current status of each extension can be followed and tried out on GitHub (see Jenkinsfile). Beneath the number stated in the title for each section, there is a branch in both declarative and scripted form that shows the full example. The result of the builds for each branch can also be seen directly on our Jenkins instance (see Jenkinsfile). As in the first part, the features of the Jenkins Pipeline plugin will be shown using a typical Java project. The kitchensink quickstart from WildFly is a useful example here as well. Since this article builds upon the examples from the first article, the numbering continues from the first part, in which five examples were shown with a simple Pipeline, own steps, stages, error handling, and properties/archiving. Thus, parallelization is the sixth example.
Parallelization (6)
Thanks to the parallel step, it is very easy to run steps or stages in parallel, thereby shortening the overall execution time of the Pipeline. The simplest solution is to execute the steps in parallel on a node. However, it should be kept in mind that the concurrent processes are executed in the same directory and can influence each other in unexpected ways. For example, two Maven builds running in parallel would delete the same target directory in the clean phase, likely causing a build to fail.
Alternatively, multiple nodes can be used for parallelization by allocating multiple Jenkins build executors. This, however, causes a great deal more overhead as the workspace must be created again on each node, meaning a Git clone, Maven dependencies may have to be loaded, etc. Therefore, parallelization within a node is the first choice in most cases.
Here is a small practical anecdote to provide motivation for parallelization: For a smaller project (approx. 10 KLOC) with higher test coverage (approx. 80%), the build time was reduced from 11 to 8 minutes by running the unit and integration test stages in parallel. Moreover, the original sequential deployment of two artifacts could be shortened from 4 to 2.5 minutes through parallelization. It is therefore worthwhile to keep the parallel step in the back of your mind to gain faster feedback without much effort.
The example in Listing 1 shows in scripted syntax how the unit and integration test stages can be concurrently run.
parallel(
unitTest: {
stage('Unit Test') {
mvn 'test'
}
},
integrationTest: {
stage('Integration Test') {
mvn 'verify -DskipUnitTests -Parq-wildfly-swarm '
}
}
)
Listing 1
A map in which the various execution branches are named and defined in a closure is sent to the parallel step. Upon execution, the entries in the log can be attributed to the respective branches using the name.
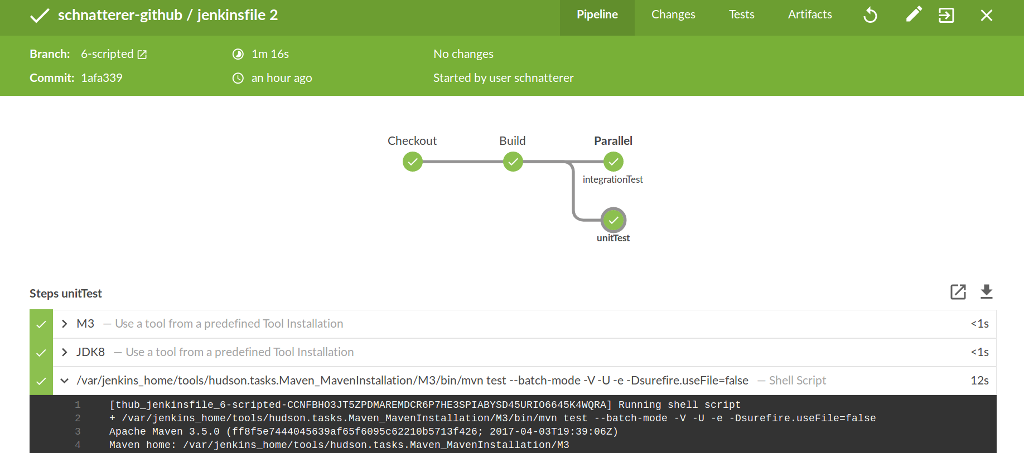
Here, the Blue Ocean plugin, already described in the first part, shows its strengths: Instead of showing the Pipeline in a single row, as in the classic view, concurrently executed branches are shown one above the other (see Figure 1). The console output of the respective branch can also be viewed in isolation and does not need to differ from the name given in the Pipeline, as in the classical view (compare Listing 2).
[integrationTest] [thub_jenkinsfile_6-scripted-CCNFBHO3JT5ZPDMAREMDCR6P7HE3SPIABYSD45URIO6645K4WQRA] Running shell script
[integrationTest] + /var/jenkins_home/tools/hudson.tasks.Maven_MavenInstallation/M3/bin/mvn verify -DskipUnitTests -Parq-wildfly-swarm --batch-mode -V -U -e -Dsurefire.useFile=false
[unitTest] [thub_jenkinsfile_6-scripted- CCNFBHO3JT5ZPDMAREMDCR6P7HE3SPIABYSD45URIO6645K4WQRA] Running shell script
[unitTest] + /var/jenkins_home/tools/hudson.tasks.Maven_MavenInstallation/M3/bin/mvn test --batch-mode -V -U -e -Dsurefire.useFile=false Listing 2
Listing 2
The parallel step can also be used in declarative syntax. Listing 3 shows how this can be represented using nested stages.
stage('Tests') {
parallel {
stage('Unit Test') {
steps {
mvn 'test'
}
}
stage('Integration Test') {
steps {
mvn 'verify -DskipUnitTests -Parq-wildfly-swarm '
}
}
}
}
Listing 3 For more complex scenarios, locks and/or the Milestone plugin can be used to synchronize several simultaneous builds. An example of each of these in use can be found here).
Nightly builds (7)
Many teams have their CI server handle long-running or regularly executing tasks once per day, typically at night. One example of this is the check of their dependencies for known security vulnerabilities (see J.Schnatterer: “Automatisierte Überprüfung von Sicherheitslücken in Abhängigkeiten von Java-Projekten,” Java Aktuell 01-2017). These nightly builds are also possible in a Jenkins Pipeline. It is very simple to regularly execute a build. Listing 4 shows how this is written in scripted syntax using properties which were described in the first article.
properties([
pipelineTriggers([cron('H H(0-3) * * 1-5')])
])
Listing 4 When the Jenkins file runs, the specified Jenkins runs are planned. Listing 4 shows how a schedule can be written in a syntax based on cron jobs:
- Minute (0-59),
- Hour (0-23),
- Day of the month (1-31),
- Month (1-12),
- Day of the week (0-7), 0 and 7 are Sunday
The asterisk (*) stands for “any valid value.” In Listing 4, for example, this means “any day in any month.” The H stands for the hash of the job name. In the process, a numerical value based on the hash value of the job name is generated. This makes it so that not all jobs with the same schedule cause peak loads. For example,
'0 0 * * 1-5'would cause all jobs to start simultaneously each workday at exactly midnight.'H H(0-3) * * 1-5'on the other hand would distribute this load throughout the period from midnight to 3 a.m.
This best practice should be used as often as possible.
For those who find this too complicated, the aliases @yearly, @annually, @monthly, @weekly, @daily, @midnight, and @hourly are available. These also use the hash system described above for load distribution. For example, @midnight specifically means between 12:00 a.m. and 2:59 a.m.
The schedule is also specified in the same way using declarative syntax (see Listing 5), however, this is written here with its own triggers directive.
pipeline {
agent any
triggers {
cron('H H(0-3) * * 1-5')
}
}
Listing 5
The greater challenge, however, is to decide where the logic for nighttime execution should be described. Here are two options.
Another Jenkins file is created in the repository, for example, Jenkinsfile-nightly. A new Pipeline or multibranch Pipeline job is created in Jenkins, and the repository and the name of the new Jenkins file that is to be read are entered again. The advantage of this is that it is easy to set up and provides a degree of separation of concern. Instead of a monolithic Jenkins file with a large number of stages that execute when triggered, there are two Jenkins files for which all stages always run. This is contrary to Pipeline thinking, where every build always runs through the same stages. Moreover, a certain degree of redundancy between the two pipelines cannot be avoided. For example, the build stage is necessary in most cases for both pipelines. This redundancy can of course be addressed with shared libraries or the load step (see below); however, this increases effort and complexity. Moreover, an additional job is more difficult to manage, particularly if one runs multibranch Pipeline jobs or even a GitHub organization. There, new jobs are created dynamically for each repository and each branch (see first part of the article series). As a result, one ends up with multiple multibranch build jobs, for GitHub organizations even an additional multibranch build job per repository, that contain the nightly builds.
Alternatively, all stages can be kept in a Jenkins file and a distinction made regarding which stages are always run and which are only executed at night. One can also specify which branches are to be built at night. This approach fits with Pipeline thinking. By doing this, one can take full advantage of the benefits offered by multibranch Pipeline jobs, since every dynamically generated branch can also be built at night if desired. Currently, this approach has the big disadvantage that queries of the build trigger are cumbersome.
Due to the described disadvantages of an additional job, making a distinction within the job makes more sense. In the following it will be shown how this can be achieved in practice.
Similar to classic freestyle jobs, the build triggers (build causes) can be queried in the pipeline. Currently, however, this can only be done using the currentBuild.rawBuild object. Access to this must be granted by a Jenkins administrator (script approval). This can be done on the Web at https://JENKINSURL/scriptApproval/ or directly in the file system under JENKINS_HOME/script-approval.xml. For security reasons, Jenkins recommends that access to the object not be permitted. Nevertheless, this is currently the only method for accessing the build causes (see get-build-cause )). The solution to this is already underway, however: In the future, it will be possible to directly query the build causes via the currentBuild object (see Jenkins issue), for which no script approval will be required.
With this script approval, execution of the integration test can be limited to the nightly build, for example (see Listing 6).
boolean isTimeTriggered = isTimeTriggeredBuild()
node {
// ...
stage('Integration Test') {
if (isTimeTriggered) {
mvn 'verify -DskipUnitTests -Parq-wildfly-swarm '
}
}
//...
}
boolean isTimeTriggeredBuild() {
for (Object currentBuildCause : script.currentBuild.rawBuild.getCauses()) {
return currentBuildCause.class.getName().contains('TimerTriggerCause')
}
return false
}
Listing 6
Here as well, the logic for querying the build cause is stored in its own step. It is worth noting that this step is called outside the node. It could also be called directly in the integration test stage. In this case, however, the request for script approval would not be received, since the build executor (node) does not send this back to the master.
To execute this example, both inputs from Listing 7 are required in script_approval.xml:
<approvedSignatures>
<string>method hudson.model.Run getCauses</string>
<string>method org.jenkinsci.plugins.workflow.support.steps.build.RunWrapper getRawBuild</string>
</approvedSignatures>
Listing 7
As described above, the methods can also be released via the Web. However, the methods must be individually and sequentially approved:
Run build → error → approve getRawBuild → run build → error → approve getCauses → run build → success.
For those who find this too complicated, the workaround shown in Listing 8 may be helpful.
boolean isNightly() {
return Calendar.instance.get(Calendar.HOUR_OF_DAY) in 0..3
}
Listing 8 Here the clock time is used to decide whether the build runs at night. This has the disadvantage that builds started by other means (for example, by SCM or manually) are also considered to be nightly builds. It should also be kept in mind that the times are based on the time zone of the Jenkins server. Regardless of the build cause, there is always the option of only building certain branches at night. Listing 9 shows what this looks like in scripted syntax.
node {
properties([
pipelineTriggers(createPipelineTriggers())
])
// ...
}
def createPipelineTriggers() {
if (env.BRANCH_NAME == 'master') {
return [cron('H H(0-3) * * 1-5')]
}
return []
}
Listing 9
The same thing can be achieved using declarative syntax, but this has to be expressed differently. For this there is the when directive, which can be used to determine whether/when a stage should be executed. Only the steps provided by Jenkins or a shared library (see below) can be used for this directive, however. Querying is not possible within the Pipeline-defined steps (such as isTimeTriggeredBuild() or isNightly()). However, the method code can be used there directly, as shown by Listing 10.
stage('Integration Test') {
when { expression { return Calendar.instance.get(Calendar.HOUR_OF_DAY) in 0..3 } }
steps {
mvn 'verify -DskipUnitTests -Parq-wildfly-swarm '
}
}
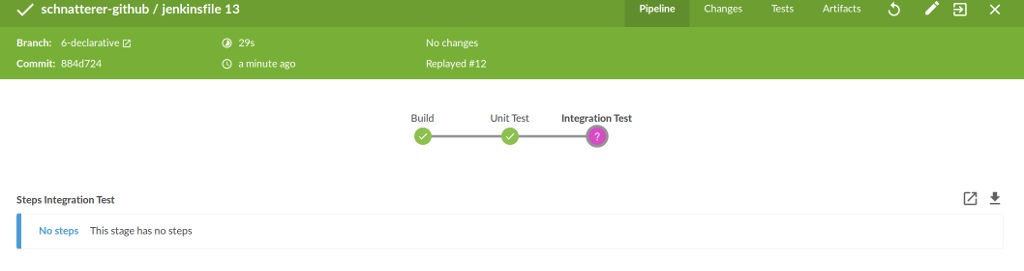
Listing 10 An advantage of declarative syntax is better integration into Blue Ocean. If a stage is skipped due to a negative result from the when directive, this is visualized in Blue Ocean accordingly (see Figure 2). This is not possible with scripted syntax.
Using declarative syntax to only build certain branches at night is not intuitive, since the triggers directive shown above cannot be run conditionally. A temporary solution is provided by the declarative syntax of the script step or by calling self-defined steps. These can be used to execute scripted syntax. The triggers can be specified in the scripted properties. One disadvantage is that these can only be executed within a stage, as shown in Listing 11.
Pipeline {
// ...
stages {
stage('Build') {
steps {
// ...
createPipelineTriggers()
}
}
}
// ...
}
void createPipelineTriggers() {
script {
def triggers = []
if (env.BRANCH_NAME == 'master') {
triggers = [cron('H H(0-3) * * 1-5')]
}
properties([
pipelineTriggers(triggers)
])
}
}
Listing 11
Conclusion and outlook
This shows how the execution time for the Pipeline can be shortened. Parallelization makes this really easy. Another option is the outsourcing of long-running stages into the nightly build. As of now, this process requires still requires some more effort. This consolidation is a sample for the third part, which introduces more helpful tools: Shared Libraries and Docker© tools. They ease the handling of Pipelines by facilitating reuse in different Jobs, unit testing of the Pipeline code, and the usage of containers.
+++ You can download the original article (German), published in Java Aktuell 02/2018.+++
Individual consulting services
Create the optimal framework for first-class software development in your company – with Cloudogu.
Request consulting
This article is part 2 of the series „Jenkins Pipeline for continuous delivery“.
Read all articles now:


