


11.09.2023
in DevOps
GitOps-Repository-Strukturen und -Patterns Teil 3: Repository Patterns
Inhaltsverzeichnis
In dieser Artikelserie stelle ich Ihnen unterschiedliche Strukturen und Patterns vor, die Sie nutzen können, um Ihren GitOps-Prozess zu designen. In diesem dritten Teil geht es um Repository Patterns, welche die Frage nach der Anzahl der GitOps-Repos beantworten. In dieser Kategorie gibt es einige Patterns zur Auswahl. Die Auswahl muss jedoch nicht exklusiv getroffen werden. Einige Patterns lassen sich auch gut kombinieren. Eine Einführung in die Thematik der GitOps-Repository-Patterns und -Strukturen bekommen Sie im ersten Teil dieser Serie, im zweiten Teil stelle ich Operator-Deployment-Patterns vor, im vierten Teil Promotion Patterns und im fünften Teil Verdrahtungs-Patterns. Im sechsten Teil zeige ich unterschiedliche Umsetzungen der Strukturen und Patterns anhand von Beispiel-Repositories.
Monorepo
Wenn die gesamte Konfiguration in einem einzigen Repo gespeichert wird, spricht man von „Monorepo“. Es ist fraglich, ob die typischen Vorteile von Monorepo in der Softwareentwicklung, wie sie von einigen Big-Tech Unternehmen eingesetzt werden, beispielsweise einfacheres Refactoring und Dependency Management, auch für GitOps gelten. Nachteile von Monorepos sind oft schwieriger zu konfigurierende Autorisierung pro Ordner und schlechte Performance durch das große Repo, aufgrund der vielen Commits. Das Gegenteil von Monorepo wird manchmal als „Polyrepo“ bezeichnet. Der Begriff Polyrepo bezeichnet allerdings nicht ein einzelnes Pattern.
Repo per Team
Wenn mehrere Repos angelegt werden, denken die meisten zuerst an das „Repo per Team“ Pattern. Verallgemeinert wird statt Team auch manchmal der Begriff „Tenant“ (Mandant) verwendet. Dies bietet den Vorteil, dass die Autorisierung auf Repo-Ebene im Source Code Management (SCM) typischerweise einfach zu handhaben ist. Außerdem fühlt es sich oft natürlich an, die Strukturen der Organisation nachzubilden, wie bereits eingangs erwähnt (Stichwort Gesetz von Conway). Zudem wird jedem Team auch nur das angezeigt, was es betrifft, was Komplexität und „mental Load“ verringert.
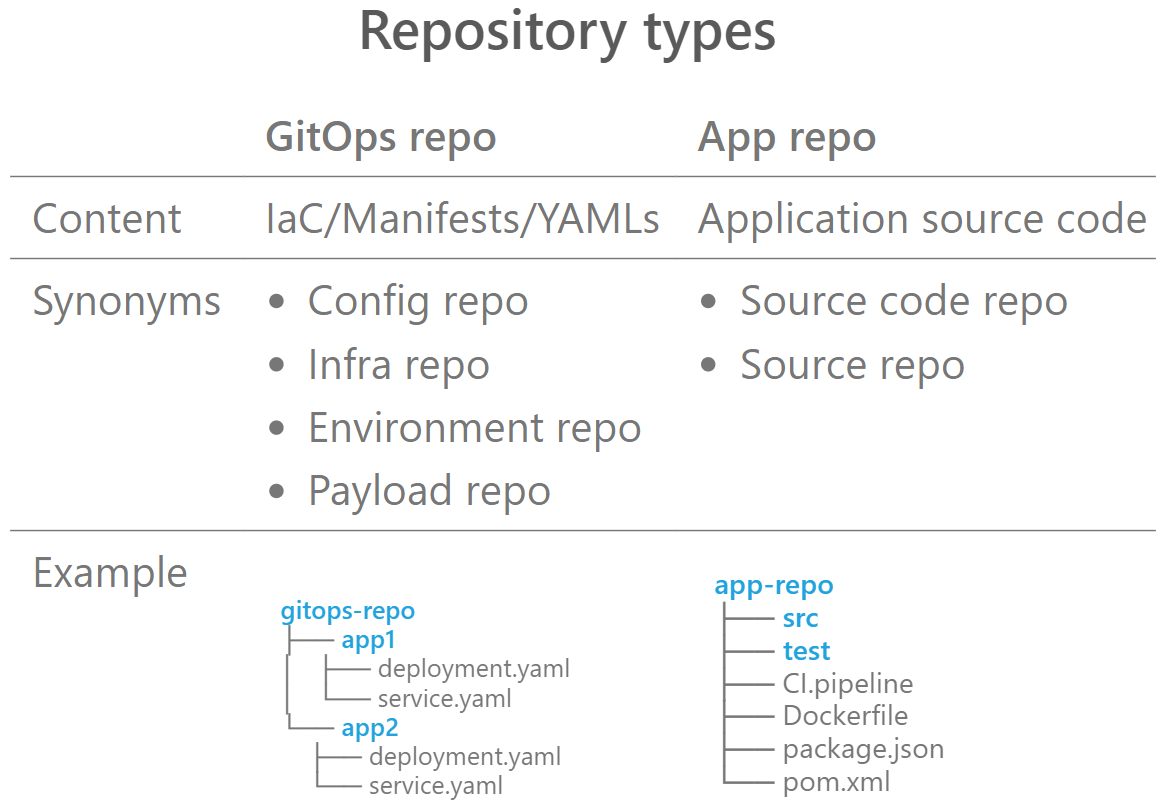 Abbildung 1: GitOps-Repository vs. App-Repository
Abbildung 1: GitOps-Repository vs. App-Repository
Repo per App
Eine Alternative bietet das „Repo per App“ Pattern. Dieses Pattern wird häufig bei selbst entwickelten Apps angewandt. Der Begriff „selbst entwickelte Apps“ ist hier im Gegensatz zu Off-the-shelf/3rd-Party-Apps zu verstehen, die betrieben, aber nicht selbst entwickelt werden. Das Pattern hat den Vorteil, dass alles, was zu einer Anwendung gehört, in einem Repo liegt. Dazu gehören der Code der Anwendung, Dokumentation und Config. Config meint beispielsweise Kubernetes-Ressourcen, teilweise wird hier von „Infra As Code“ gesprochen. Source Code und Config in einem Repo abzulegen, ist vor allem bei Entwickelnden sehr beliebt. Allerdings ist empfehlenswert (beispielsweise laut Argo CD), den Source Code der Anwendung von der Config zu trennen. An dieser Stelle macht es Sinn, die Begriffe App-Repo (enthält Source Code) und GitOps-Repo abzugrenzen.
Abbildung 1 zeigt eine Gegenüberstellung und weitere Synonyme. Die Trennung von App-Repo und GitOps-Repo hat unter anderem den Vorteil, dass die gesamte Config (beispielsweise eines Teams mit mehreren Anwendungen oder eines ganzen Clusters) an einer zentralen Stelle ist und dort besser auditiert und durchsucht werden kann. Auch für die Automatisierung des Aktualisierens neu gebauter Image-Versionen mit dem CI-Server hat diese Trennung Vorteile, da sie Endlosschleifen von Build Jobs und Git Pushes vermeidet. Andererseits ist genau das auch ein Nachteil, da kein CI-Job vorhanden ist, um beispielsweise statische Code Analysen durchzuführen. Was nun?
Config Replication
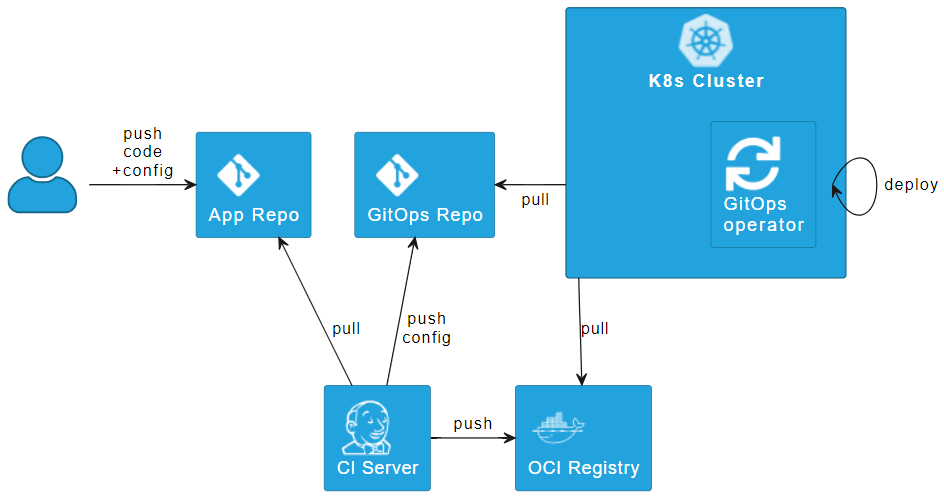 Abbildung 2: Implementierung von Repo per App mittels Config Replication
Abbildung 2: Implementierung von Repo per App mittels Config Replication
Ein Kompromiss kann es sein, das „Repo per App“ Pattern durch „Config Replication“ zu implementieren. Dabei bleibt die Config im App-Repo und wird dann vom CI-Server in das GitOps-Repo gepusht. Dabei kann der CI-Server außerdem zur Umsetzung von Shift left genutzt werden: Er kann statische Code-Analysen durchführen. Anbei einige konkrete Toolvorschläge: Mittels yamllint können einfache Syntaxfehler früh gefunden werden. Kubeconform verhindert, dass Kubernetes Ressourcen Felder verwenden, die nicht im Schema des API-Servers vorhanden sind. Mittels Helm Lint können Fehler in Helm Charts gefunden werden.
Tipp: Auch für Helm Charts können Schema generiert und validiert werden. Mit conftest können OpenPolicyAgent Policies schon vor dem Deployment auf den Cluster validiert werden. Außerdem gibt es eine große Anzahl an Security-Scannern, die sicherstellen, dass keine unsicheren Configs im Cluster landen. Im Rahmen der CNCF wird beispielsweise kubescape entwickelt.
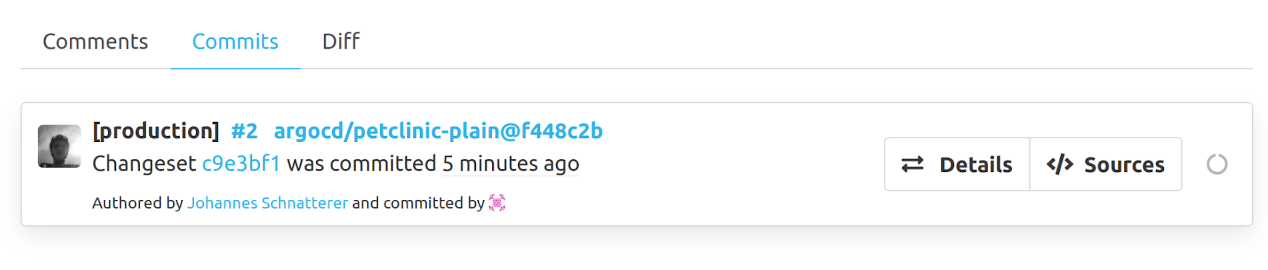 Abbildung 3: Beispiel Pull Request
Abbildung 3: Beispiel Pull Request
Der CI-Server kann außerdem für weitere Automatisierung sorgen, beispielsweise für die Promotion (dazu mehr im nächsten Teil dieser Serie) oder um Commits und Pull Requests mit weiteren Informationen zu versehen. Abbildung 3 zeigt hier ein Beispiel. Darin enthält der Commit ein Präfix für das Environment (hier „production“), einen Link zum Issue Tracker (verbindet die Config mit der User Story) und einen Link zum zugehörigen Commit im App-Repo. Als Autor wird der Autor des Commits im App-Repo genannt, als Committer der CI-Server, um klarzustellen, dass dies ein generierter Commit ist.
Natürlich hat auch Config Replication nicht nur Vorteile. Ein Nachteil ist die Komplexität der entstehenden Pipelines. Um die Logik nicht für jede Anwendung duplizieren zu müssen, macht es Sinn, hier etwas Wiederverwendbares zu entwickeln. Beispiele dafür sind eine GitHub Action oder eine Jenkins Shared Library. Die Erfahrung zeigt, dass einiges an Aufwand anfällt, bis das alles resilient funktioniert. Beispielsweise kann die Concurrency im Zusammenspiel mit Git und automatische Merges riskant sein (Retry-Strategien und Gefahr von Inkonsistenz) und die angesprochenen fortgeschrittenen Features, wie statische Code-Analyse und Informationen in Commits können zusätzlichen Aufwand verursachen. Es ist also empfehlenswert hier etwas Bestehendes zu verwenden, statt selbst zu bauen. Ein Beispiel ist die GitOps-Build-Lib für Jenkins. Mit ihr wurde auch der in Abbildung 3 gezeigte Commit erstellt. Ein weiterer Nachteil ist die Redundanz der Config. Sie besteht einmal im App-Repo und einmal im GitOps-Repo.
Repo Pointer
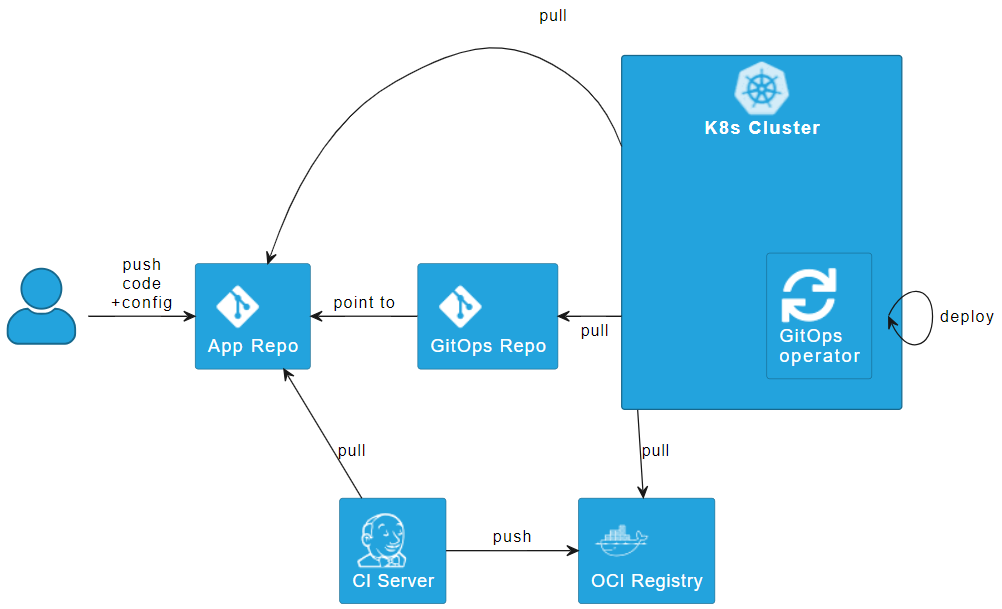 Abbildung 4: Implementierung Repo per App mittels Repo Pointer
Abbildung 4: Implementierung Repo per App mittels Repo Pointer
Stört die Redundanz, so kann das „Repo per App“ Pattern alternativ durch einen „Repo pointer“ implementiert werden, wie ihn Abbildung 4 schematisch zeigt. Dabei wird der Code nicht repliziert, sondern aus dem GitOps-Repo auf das App-Repo verwiesen. Dies kann beispielsweise mit einer Application Custom Resource (CR) in Argo CD oder einer Kustomization CR in Flux realisiert werden. Der GitOps-Operator zieht sich dann die Config direkt aus dem App-Repo. Denkbar wäre auch der Git-native weg über Submodules. Die Verwendung von CRs ist erfahrungsgemäß aber benutzbarer. Auch dieses Vorgehen hat seine Nachteile. Beispielsweise muss der GitOps-Controller auf viele Repos autorisiert werden und das GitOps-Repos ist nicht mehr die zentrale Stelle für Config, sondern enthält nur noch Links.
Repo per Environment
Ein letztes Pattern, das in Bezug auf Repositories denkbar ist, ist „Repo per environment“ (auch „Environment per Repo“ oder mit dem Begriff „Stage“ statt „Environment“). Hier wird ein Repository für jedes Environment (beispielsweise Development, Staging, Production) angelegt. Dieses Pattern wird selten gewählt, da es zu einer großen Zahl an Repositories und zu einem weniger automatisierten, umständlicheren GitOps-Prozess führt. Gründe, sich dafür zu entscheiden, sind meist organisatorische Anforderungen. Beispielsweise wenn Developers nicht auf Produktion zugreifen dürfen oder eine Autorisierung auf Ordnern innerhalb eines Git-Repos nicht möglich oder isoliert genug ist. Ein weiterer Anwendungsfall ist, wenn Releases von einem Security-Team freigegeben werden müssen.
Fazit
Die unterschiedlichen Repository Patterns bieten die Möglichkeit, den GitOps-Prozess an die eigenen Anforderungen anzupassen. Weitere Möglichkeiten bieten die in den anderen Teilen dieser Artikelserie vorgestellten Patterns: Operator Deployment Patterns, Promotion Patterns, Verdrahtungs-Patterns und Real-Life-Beispiele.
Individuelle Beratung für Sie
Schaffen Sie mit uns den optimalen Rahmen für erstklassige Softwareentwicklung in Ihrem Unternehmen.
Zum GitOps Consulting

