


07.09.2023
in DevOps
GitOps-Repository-Strukturen und -Patterns Teil 2: Operator Deployment Patterns
In dieser Artikelserie stelle ich Ihnen unterschiedliche Strukturen und Patterns vor, die Sie nutzen können, um Ihren GitOps-Prozess zu designen. In diesem zweiten Teil geht es um Patterns im Bereich der Operator Deployments. Diese beschreiben, wie viele GitOps-Operatoren man im Verhältnis zu Kubernetes Clusters oder Namespaces deployt. Eine Einführung in die Thematik der GitOps-Repository-Patterns und -Strukturen bekommen Sie im ersten Teil dieser Serie, im dritten Teil stelle ich Repository-Patterns vor, im vierten Teil Promotion Patterns und im fünften Teil Verdrahtungs-Patterns. Im sechsten Teil zeige ich unterschiedliche Umsetzungen der Strukturen und Patterns anhand von Beispiel-Repositories.
 Abbildung 1: Deployment Instance per Cluster
Abbildung 1: Deployment Instance per Cluster
„Instance per Cluster“ (Synonym: „Standalone“) bezeichnet die Verwendung von einem GitOps-Operator mit einem Kubernetes Cluster, siehe Abbildung 1. Dieses Pattern bietet starke Isolation. Diese hat zum einen Vorteile in Bezug auf Security, da im Falle eines Einbruchs nur die Anwendungen der einen Instanz in Gefahr sind. Zum anderen skaliert dieses Vorgehen besser in Bezug auf Last und Downtime. Der Nachteil ist der Aufwand für die Wartung, da statt einer zentralen Instanz mehrere betrieben werden müssen. Außerdem steigt der Ressourcenbedarf.
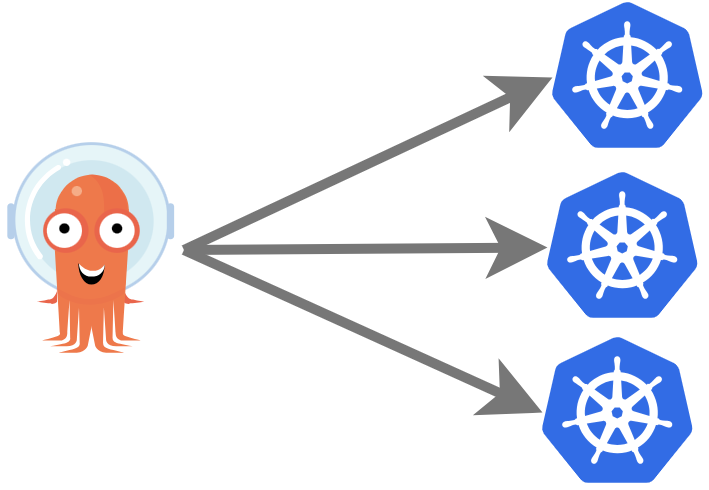 Abbildung 2: Deployment Hub and Spoke
Abbildung 2: Deployment Hub and Spoke
Im Gegensatz dazu steht das Pattern „Hub and Spoke“ (Nabe und Speiche), siehe Abbildung 2. Hier kommt ein zentraler GitOps-Operator für mehrere Kubernetes Cluster zum Einsatz. Entsprechend sind die Vorteile und Nachteile genau invertiert zum Instance per Cluster Pattern: Der Wartungsaufwand ist geringer, dafür gibt es einen Single Point of Failure, was schlechter skaliert und weniger sicher ist.
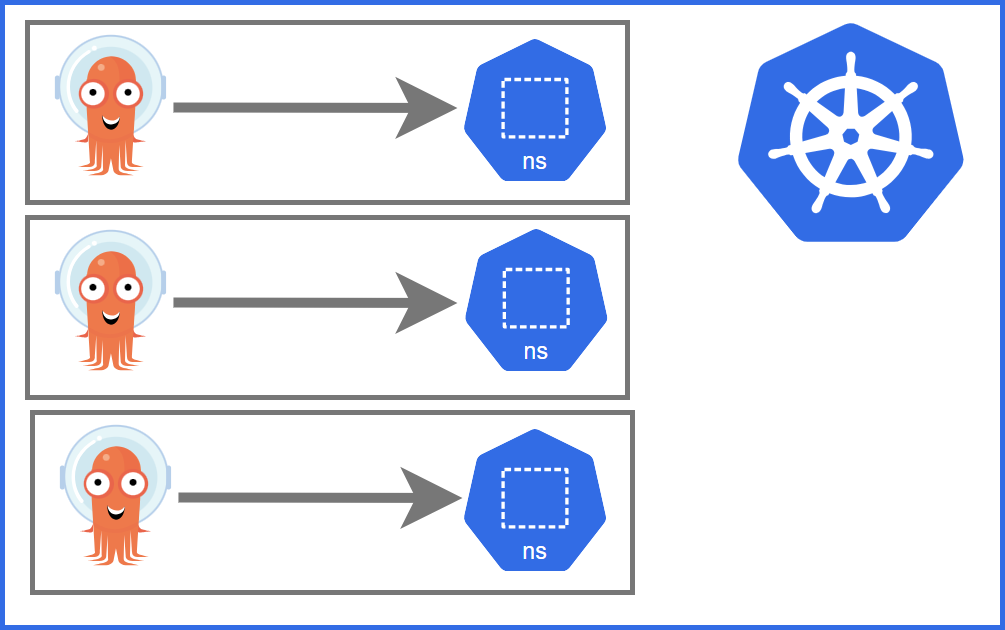 Abbildung 3: Deployment Instance per Namespace
Abbildung 3: Deployment Instance per Namespace
Das Pattern „Instance per Namespace“ (Synonym „Namespaced“) ist ähnlich zu „Instance per Cluster“, allerdings wird hier ein Operator pro Namespace betrieben, statt pro Cluster, siehe Abbildung 3. Die Verwendung dieses Patterns kann sinnvoll sein, wenn eine hohe Isolation angestrebt wird, aber der Betrieb eigener Kubernetes Cluster nicht in Frage kommt. Die kann beispielsweise aufgrund hoher Kosten On-Premises oder aufgrund organisatorischer Einschränkungen vorkommen. Dieses Pattern hat prinzipiell die gleichen Vorteile wie „Instance per Cluster“. Zu beachten ist, dass die Isolation von Kubernetes Namespaces generell geringer ist, als bei getrennten Clustern. Auch ist zu beachten, ob Operators die Unterteilung in Namespaces überhaupt unterstützen.
Über diese grundlegenden Patterns hinaus gibt es noch Mischformen, wie sie beispielsweise Nicholas Morey in seinem Artikel How many do you need? - Argo CD Architectures Explained vorstellt. In seinem Post A Comprehensive Overview of Argo CD Architectures beschreibt Dan Garfield darüber hinaus noch die Patterns „Split Instance“ und „Control Plane“. Aus Erfahrung des Autors spielen diese aber (noch) keine zentrale Rolle.
Fazit
Mit den unterschiedlichen Operator Deployment Patterns gibt es momentan drei etablierte Ansätze, die jeweils ihre eigenen Vor- und Nachteile haben. Abhängig von Ihren Anforderungen können Sie das am besten passende für sich auswählen.
In den folgenden Artikeln werden noch Repository Patterns, Promotion Patterns, Verdrahtungs-Patterns und Real-Life-Beispiele vorgestellt.
Individuelle Beratung für Sie
Schaffen Sie mit uns den optimalen Rahmen für erstklassige Softwareentwicklung in Ihrem Unternehmen.
Mehr über GitOps Consulting erfahren

