


05.09.2023
in DevOps
GitOps-Repository-Strukturen und -Patterns Teil 1: Einführung und Überblick
Inhaltsverzeichnis
Ein zentraler Punkt bei der Einführung von GitOps ist das Design des GitOps-Prozesses und der zugehörigen Repositories. Hier stellen sich Fragen nach
- der Struktur der Repositories,
- Umsetzung von Stages/Environments,
- Verwendung von Branches,
- Verhältnis der Anzahl von GitOps-Operators zur Anzahl Cluster und/oder Namespaces und
- wie am Ende alles verdrahtet werden soll.
Diese Artikelserie geht auf diese Fragen ein und benennt dabei wiederkehrende Elemente als GitOps-Patterns. Eine Übersicht der hier beschriebenen Patterns bietet das Repository cloudogu/gitops-patterns bei GitHub.
Der Abgrund zwischen echter Welt und Infrastruktur
Stellen wir uns vor wir wären dabei GitOps in unserer Organisation einzuführen. Ein GitOps-Operator ist bereits ausgewählt. Häufig fällt hier die Wahl auf Flux oder Argo CD (für einen Vergleich siehe diesen Artikel). Nun geht es darum, den GitOps-Prozess zu entwerfen. An dieser Stelle steigt der Artikel ein.
Eine wichtige Frage ist die nach dem Anwendungsfall. Was soll eigentlich per GitOps deployt werden? Infrastruktur oder Anwendungen? Dies kann das Design beeinflussen. Dieser Artikel geht vom wahrscheinlich häufigsten Anwendungsfall aus: dem Deployment von Anwendungen.
Spannend ist auch die Verantwortlichkeit: Wer kümmert sich in einer Organisation um den GitOps-Prozess? Je nach Team-Topologie und Grad der Team-Autonomie kümmern sich Applikations-Teams selbst um den GitOps-Operator oder delegieren dies. Die Komplexität von Kundenanforderung und Produktentwicklung auf der einen, bis hin zu stark auf Betrieb bezogenen Themen wie GitOps auf der anderen Seite ist sehr hoch. Unter anderem deshalb setzt sich vermehrt das Thema Platform Engineering durch. Hier entwickelt und betreibt ein dediziertes Platform- oder Infra-Team eine sogenannte „Internal Developer Platform“ für die Applikations-Teams. Der Fokus liegt dabei auf „Developer Experience“: Für die Applikations-Teams soll es einfach sein, ihre Anwendungen zu deployen und zu betreiben.
In einem solchen Szenario liegt es nahe, dass das Platform-Team den GitOps-Prozess designt und Abstraktionen schafft, die einen Teil der Gesamtkomplexität verstecken. Ziel ist die einfache Benutzbarkeit und Self-Service für die Applikations-Teams. Bei dieser Diskussion über Teams und Software-Produkte liegen Gedanken an das Gesetz von Conway nahe. Conway erkannte eine Gesetzmäßigkeit bei der Architektur von Software-Systemen: Die Kommunikationsstrukturen in einer Organisation haben direkten Einfluss auf das Design. Dies trifft auch beim Design des GitOps-Prozesses zu. Insofern gibt es absichtlich keinen Standard für GitOps-Prozesse und für die Struktur der zugehörigen Repositories (Repos). Jede Organisation ist verschieden, also werden auch die GitOps-Prozesse unterschiedlich sein.
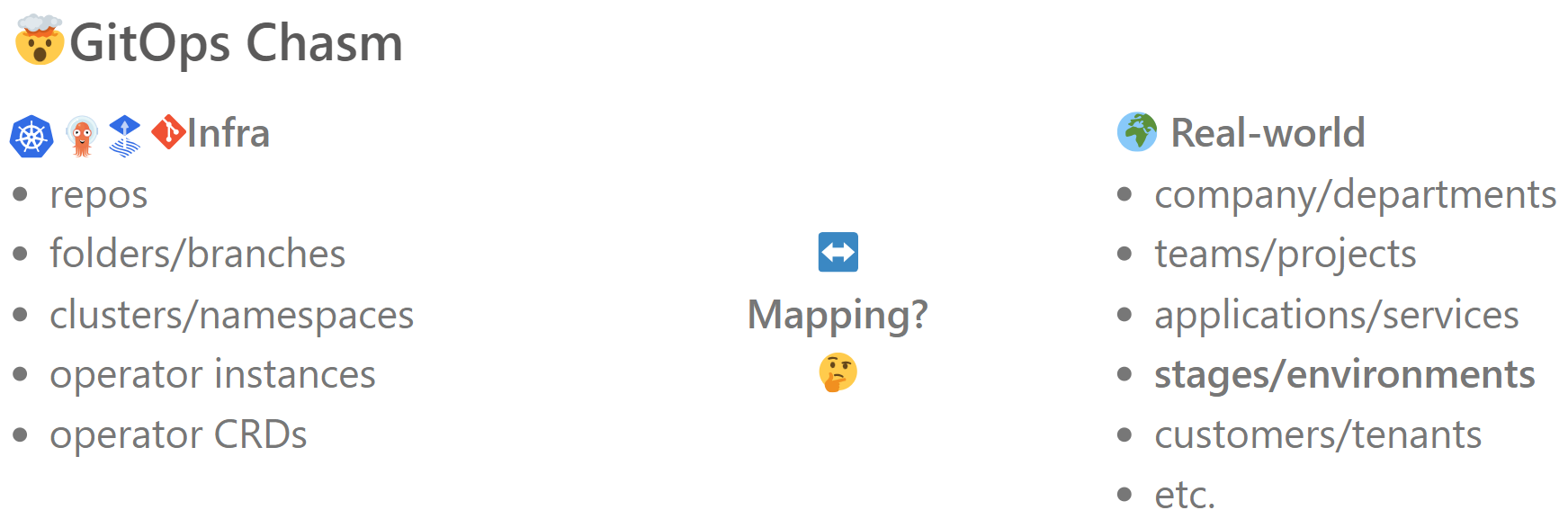
Was ist beim Design dieser Prozesse eigentlich zu tun? Die Herausforderung ist die Abbildung der „echten Welt“ auf die Infrastruktur (siehe Abbildung unten). Diese Abbildung kann man sich bildlich wie einen Abgrund vorstellen, den es zu überwinden gilt – den GitOps Chasm (engl. für tiefe Kluft). Der GitOps Chasm ist Herausforderung und Chance zugleich. Zur Überwindung ist ein Konzept zur Abbildung der „echten Welt“ auf die Infrastruktur notwendig. Beispielsweise: Werden Teams als Ordner, Branches oder Repositories abgebildet? Bekommt jedes Team eigene Cluster? Wird jedes Environment als eigener Cluster abgebildet? Dieses Konzept sorgt für Struktur und damit Wartbarkeit. Dieses Konzept sorgt für Struktur und damit Wartbarkeit. Ein Start mit GitOps hat damit einen klaren Vorteil. Andernfalls würde man ohne Konzept von verschiedenen Stellen, Repos, CI-Jobs oder manuell auf den Cluster deployen. Auf lange Sicht kann keiner mehr nachvollziehen, wer wann was wieso deployt hat.
Kategorien von GitOps-Patterns
Zwar gibt es nicht den einen GitOps-Prozess, der zu jeder Organisation passt, aus der Erfahrung zeigen sich jedoch gewisse wiederkehrende Elemente. Wir können also von Patterns sprechen. Mehr oder weniger synonym zu Patterns tauchen folgende Begriffe in Literatur und in Vorträgen auf: Strategies, Models, Approaches, Best Practices. Bisher sind diese Patterns weder einheitlich benannt noch kategorisiert. Zeit, dies zu ändern! Im Folgenden werden GitOps-Patterns in den folgenden Kategorien benannt und beschrieben:
- Operator Deployment – Verhältnis Anzahl GitOps-Operatoren zu Kubernetes Clusters und Namespaces.
- Repository – Wie viele GitOps Repos werden eingesetzt?
- Promotion – Wie werden Stages/Environments modelliert?
- Verdrahtung – Bootstrapping des Operators, Verbinden der Repos, Branches und Ordner, Gruppieren von Ressourcen
Viele der Namen für die Patterns werden auch in anderer Literatur verwendet. Eine Übersicht der Pattern und Quellen findet sich in Repository cloudogu/gitops-patterns.
In den folgenden Teilen dieser Artikelserie werde ich Ihnen die unterschiedlichen GitOps-Patterns genauer vorstellen: Operator Deployment Patterns, Repository Patterns, Promotion Patterns, Verdrahtungs-Patterns und Real-Life-Beispiele.
Individuelle Beratung für Sie
Schaffen Sie mit uns den optimalen Rahmen für erstklassige Softwareentwicklung in Ihrem Unternehmen.
Zum GitOps Consulting

