


19.04.2018
in Technology
Coding Continuous Delivery – Grundlagen des Jenkins Pipeline Plugins
Inhaltsverzeichnis
+++ Der Originalartikel kann hier heruntergeladen werden: Zeitschriftenartikel, veröffentlicht in Java Aktuell 01/2018. +++
Wer schon einmal eine Continuous-Delivery-Pipeline mit einem herkömmlichen CI-Tool durch Verketten einzelner Jobs und ohne direkten Pipeline-Support eingerichtet hat, der weiß, wie unübersichtlich ein solches Unterfangen werden kann. Diese Artikelserie zeigt, wie sich eine Pipeline mit Hilfe des Jenkins Pipeline-Plugins an zentraler Stelle als Code definieren lässt. Im ersten Teil dieser Artikelserie geht es dabei um die Grundlagen und um praktische Tipps für den Einstieg.
Continuous Delivery hat sich im Umfeld agiler Softwareentwicklung als adäquates Vorgehen erwiesen, qualitativ hochwertige Software in kurzen Zyklen zuverlässig und wiederholbar zu veröffentlichen. Dabei durchlaufen Änderungen an der Software eine Reihe von qualitätssichernden Schritten, ehe sie in Produktion ankommen. Eine typische Continuous-Delivery-Pipeline könnte z. B. so aussehen:
- Checkout aus der Versionsverwaltung
- Build
- Unit-Tests
- Integrationstests
- Statische Code-Analyse
- Deployment in einer Staging-Umgebung
- Funktionale und/oder manuelle Tests
- Deployment in Produktion
Dabei ist es essenziell, all diese Schritte zu automatisieren, was typischerweise mittels Continuous Integration Servern wie Jenkins geschieht.
Zwar eignen sich herkömmliche Jenkins-Jobs gut, einzelne Schritte einer Continuous-Delivery-Pipeline zu automatisieren. Da die Schritte aber auf einander aufbauen, ist deren Reihenfolge zwingend einzuhalten. Wer mit herkömmlichen Jenkins-Jobs (oder anderen Continuous-Integration Tools ohne direkten Pipeline-Support) einmal eine Continuous-Delivery-Pipeline eingerichtet und betrieben hat, dem dürfte klar sein, dass das schnell unübersichtlich wird. Einzelne Jobs, oft angereichert um etliche Pre- und Post-Build-Schritte, werden verkettet. Dies führt dazu, dass man sich von Job zu Job hangeln muss, um zu verstehen, was passiert. Zusätzlich sind solche komplexen Konfigurationen weder test- noch versionierbar und müssen für jedes Projekt neu aufgesetzt werden.
Hier schafft das Jenkins-Pipeline-Plugin Abhilfe. Das Plugin bietet die Möglichkeit, die gesamte Pipeline mittels einer Groovy-DSL an zentraler Stelle, einer versionierten Skript-Datei (Jenkinsfile), als Code zu definieren. Dabei stehen dem Anwender zwei Varianten der DSL zur Auswahl: ein imperativer, tatsächlich eher gescripteter Stil (im Folgenden als scripted Syntax bezeichnet) und seit Februar 2017 auch eine deklarative Variante (im Folgenden als declarative Syntax bezeichnet). Die deklarative Syntax ist dabei eine Teilmenge der scripted Syntax und bietet mit einem vorgegebenen Aufbau und mehr beschreibenden Sprachelementen eine Grundstruktur (ähnlich einer maven-pom-Datei), die den Einstieg vereinfachen kann. Damit führt sie, auch wenn sie geschwätziger und unflexibler ist, zu Build-Skripten, die intuitiver verständlich sind als solche, die in scripted Syntax verfasst sind. Diese bietet dafür fast alle Freiheiten, die die Sprache Groovy mit sich bringt (Einschränkungen siehe Unterschiede zu Groovy), erfordert aber ggf. auch eine tiefergehende Auseinandersetzung mit Groovy. Die Entscheidung für die eine oder die andere Variante kann aktuell noch als Geschmacksfrage angesehen werden; es ist nicht absehbar, ob sich eine der beiden Richtungen durchsetzen und die andere letztlich verdrängen wird. Neuere offizielle Beispiele sind jedoch meist in der declarative Syntax verfasst und es gibt einen visuellen Editor, der nur auf diese ausgelegt ist. Die Beispiele in diesem Artikel sind in beiden Stilen formuliert, um dem Leser direkte Vergleichbarkeit zu bieten.
Kernkonzepte
Die Beschreibung einer Build-Pipeline mit der Jenkins-Pipeline-DSL gliedert sich im Wesentlichen in Stages und Steps. Stages sind frei wählbare Gruppierungen der Schritte einer Pipeline. Die Punkte 1. bis 8. der oben genannten Beispiel-Pipeline könnten z. B. jeweils eine Stage darstellen. Ein Step ist dabei ein Befehl, der einen konkreten Build-Schritt beschreibt und der letztlich von Jenkins ausgeführt wird. Eine Stage umfasst also einen oder mehrere Steps.
Für eine minimale Pipeline-Definition muss neben mindestens einer Stage mit einem Step noch ein Build-Executor allokiert werden, also z. B. ein Jenkins-Build-Slave. Dies geschieht in der declarative Syntax mittels der agent Section, scripted mittels node Step. In beiden Varianten kann der Executor mit Labels weiter qualifiziert werden, sodass sichergestellt ist, dass er bestimmte Bedingungen erfüllt (z. B. eine bestimmte Java-Version oder eine Docker©-Installation zu Verfügung stellt).
Bevor es an der Zeit ist, die erste Pipeline einzurichten, sei noch auf die verschiedenen Arten von Pipeline-Jobs hingewiesen, die Jenkins anbietet:
- Pipeline: Ein einfacher Pipeline-Job, der die Script-Definition direkt über die Weboberfläche von Jenkins oder in einem
Jenkinsfileaus dem Source Code Management (SCM) erwartet. - Multibranch-Pipeline: Erlaubt es ein SCM-Repository mit mehreren Branches anzugeben. Wird in einem Branch ein
Jenkinsfilegefunden, wird die darin definierte Pipeline bei Änderungen am Branch ausgeführt. Pro Branch wird dabei on-the-fly ein Jenkins-Job angelegt. - GitHub Organization: Eine Multibranch-Pipeline für eine GitHub Organization bzw. einen GitHub User. Dieser Job scannt alle Repositories einer GitHub Organization und legt für alle, deren Branches ein
Jenkinsfileenthalten, einen Folder an, der eine Multibranch-Pipeline enthält. Es handelt sich also quasi um eine geschachtelte Multibranch-Pipeline. Siehe z.B. Cloudogu Open Source Jenkins.
Erste Schritte
Um sich mit den Möglichkeiten, des Pipeline-Plugins vertraut zu machen, bietet sich das simpelste Setup an: Man baut ein Projekt ohne vorhandenes Jenkinsfile, indem man das Pipeline-Script direkt in einem Pipeline-Job über die Weboberfläche von Jenkins beschreibt.
Zum Einstieg ist es wichtig zu wissen, dass es in jeder Art von Pipeline-Job auf der Weboberfläche von Jenkins Links zur Dokumentation der auf der aktuellen Jenkins Instanz verfügbaren Pipeline-Features gibt. Die in allen Jenkins-Instanzen verfügbaren Basic Steps können durch zusätzliche Plugins erweitert werden. Klickt man im Job auf Pipeline-Syntax, gelangt man auf den Snippet Generator. Zusätzlich gibt es einen globalen Link in jeder Jenkins-Instanz.
Die URL lautet wie folgt: https://jenkins-URL/pipeline-syntax
Beispiel: https://web.archive.org/web/20230508072209/https://oss.cloudogu.com/jenkins/pipeline-syntax/
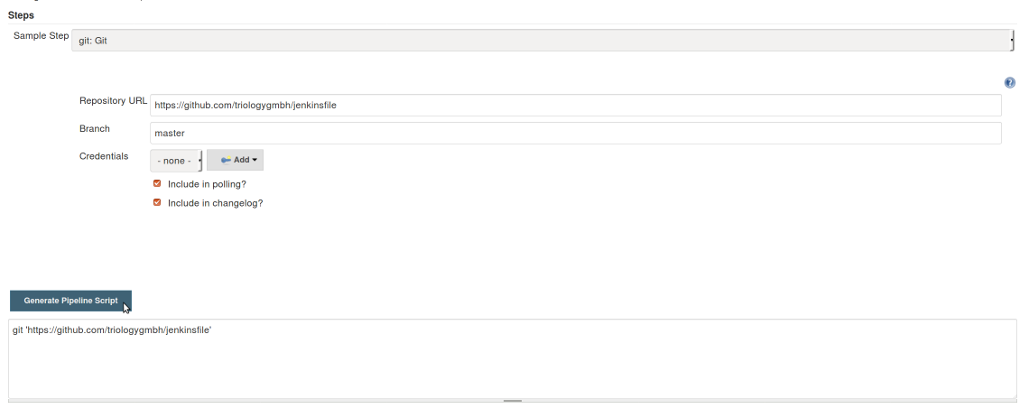
Der Snippet-Generator ist ein hilfreiches Tool für den Übergang vom bisherigen Jenkins-Job „Zusammenklicken“ zur Pipeline-Syntax. Hier kann man wie gewohnt Teile seines Build-Jobs mit der Maus zusammenstellen und sich daraus ein Snippet in Pipeline-Syntax generieren lassen (siehe Abbildung 1). Der Snippet-Generator kann aber auch später hilfreich sein, um die Syntax neuer Plugins kennenzulernen oder wenn man keine Autovervollständigung in seiner IDE hat. Apropos Autovervollständigung: Im Snippet Generator gibt es weitere Links auf hilfreiche Informationen:
- Die für diese Instanz verfügbaren globalen Variablen. Dazu gehören environment variables, Parameter des Build Jobs und Informationen zum aktuellen Build Job. Beispiel: https://web.archive.org/web/20230508072209/https://oss.cloudogu.com/jenkins/pipeline-syntax/globals
- Die ausführliche Doku aller für diese Instanz verfügbaren Steps und Classes sowie deren zugehörigen Parameter. Beispiel: https://web.archive.org/web/20230508072209/https://oss.cloudogu.com/jenkins/pipeline-syntax/html
- Eine IntelliJ Groovy DSL Datei (GDSL) mit der man Autovervollständigung aktivieren kann. Wie das funktioniert, verrät dieser Blog Post.
Pipeline-Scripts
Mit diesem Wissen kann das Schreiben von Pipeline-Scripts beginnen. Im Folgenden werden die grundlegenden Features des Jenkins Pipeline-Plugins anhand eines typisches Java Projekts gezeigt. Als Beispiel dient hier der kitchensink Quickstart von WildFly, eine typische JEE-Webanwendung mit CDI, JSF, JPA, EJB, JAX-RS und Integrationstests mit Arquillian.
Ein minimales Pipeline-Script zum Bauen dieses Projekts auf Jenkins sieht in declarative Syntax aus wie in Listing 1.
pipeline {
agent any
tools {
maven 'M3'
}
stages {
stage('Checkout') {
steps {
git 'https://github.com/cloudogu/jenkinsfiles'
}
}
stage('Build') {
steps {
sh 'mvn -B package'
}
}
}
}
Listing 1 Das Script in Listing 1
- allokiert einen beliebigen Build Executor,
- holt sich die unter Tools konfigurierte Maven-Instanz,
- checkt den default Branch der Git URL aus und
- führt einen nicht-interaktiven Maven Build aus.
Hier zeigt sich der einheitliche Aufbau der declarative Pipeline. Jede Pipeline ist umschlossen vom pipeline Block, wiederum aus Sections bzw. Directives (siehe Jenkins Pipeline Declarative Syntax) besteht. Diese spiegeln unter anderem die oben beschriebenen Kernkonzepte Stage und Step wider.
Listing 2 zeigt die Pipeline aus Listing 1 in scripted Syntax.
node {
def mvnHome = tool 'M3'
stage('Checkout') {
git 'https://github.com/cloudogu/jenkinsfiles'
}
stage('Build') {
sh "${mvnHome}/bin/mvn -B package"
}
}
Listing 2
Auch in der scripted Syntax sieht man das Konzept der Stage, dies beinhaltet dann direkt die Steps. Das Konzept der Sections bzw. Directives gibt es nicht. Bei node, tool, stage, git, usw. spricht man hier jeweils nur von Steps. In dieser Syntax hat man deutlich mehr Freiheiten. Anders als bei der declarative Syntax, die immer von einem pipeline Block umgeben sein muss, könnte man bei der scripted Syntax auch Steps außerhalb des node Blocks ausführen. Dabei zeigt sich, warum die deklarative Syntax eine Teilmenge der scripted Syntax ist: Im Prinzip ist der die declarative Pipelines umschließende pipeline Block ein Step der scripted Syntax.
Damit diese Scripts auf einer Jenkins Instanz ausführbar sind, muss auf einem Jenkins 2.60.2 auf Linux im Auslieferungszustand unter „Global Tool Configuration“ nur eine Maven Installation mit dem Namen M3 angelegt werden. Danach kann dieses mittels der tools Declarative bzw. Step im Pipeline-Job bekannt gemacht und ausgeführt werden. Im Hintergrund führt die Angabe des Tools M3 dazu, dass Maven, auf dem aktuellen Build-Executor zur Verfügung gestellt wird. Falls nötig, wird es dazu installiert und im PATH bekannt gemacht.
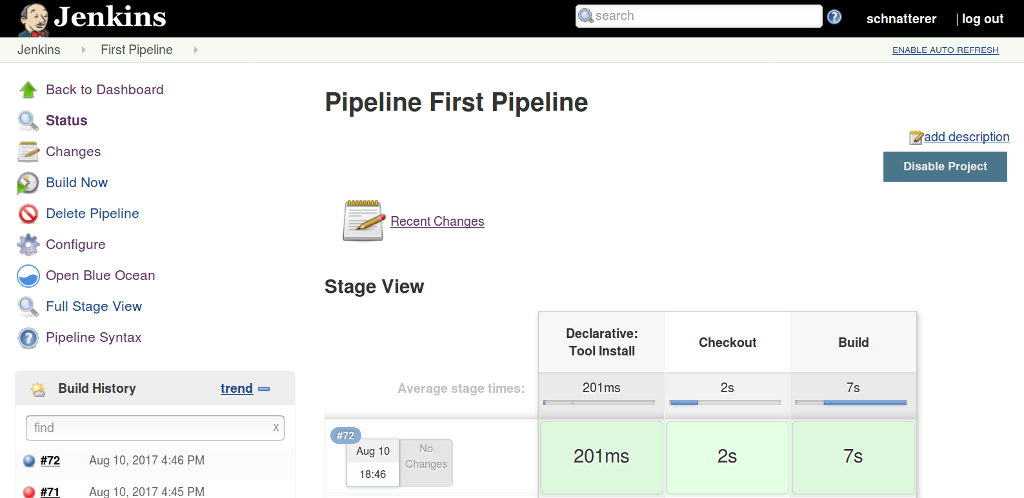
Das Ergebnis des Builds wird im classic Theme von Jenkins in einer Stage View angezeigt, in der je Build die Stages und deren Ausführungszeiten visualisiert werden, wie in Abbildung 2 gezeigt.
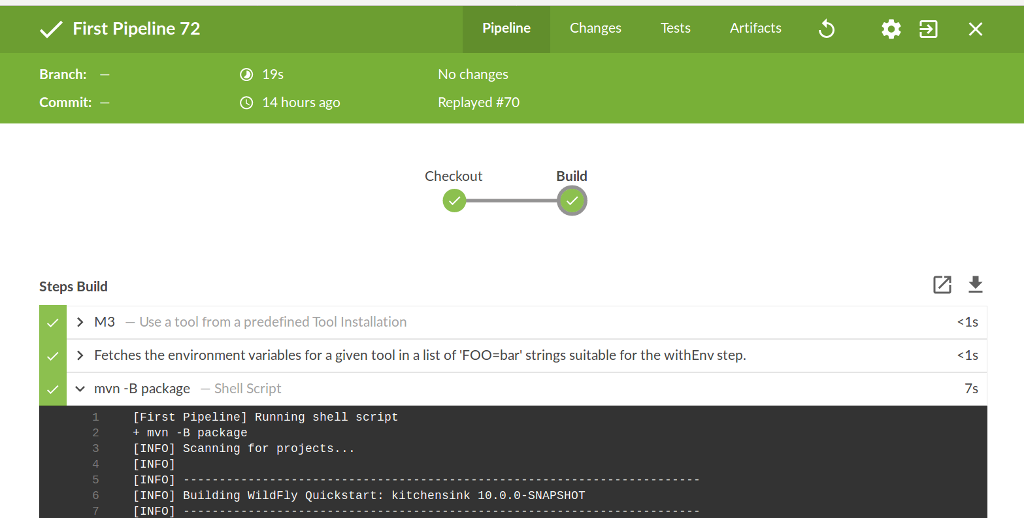
Eine spezielle für Pipelines designte Ansicht bietet das offizielle Jenkins Theme Blue Ocean. Mit deutlich modernerem UX kann hier sehr übersichtlich mit Pipelines gearbeitet werden. Man sieht auf einen Blick, welche Steps pro Stage ausgeführt wurden und kann beispielsweise das Console Log bestimmter Steps mit einem Klick einsehen. Für declarative Pipelines gibt es außerdem einen visuellen Editor. Wenn das Plugin installiert ist, kann man über Links in jedem Build Job zwischen Blue Ocean und Classic wechseln. Abbildung 3 zeigt die Pipeline aus Abbildung 2 in Blue Ocean.
Die oben gezeigten ersten Pipeline-Beispiele werden im Folgenden sukzessive erweitert, um grundlegende Features der Pipeline zu zeigen. Dabei werden die Änderungen jeweils in declarative als auch in scripted Syntax gezeigt. Den aktuellen Stand jeder Erweiterung kann man bei Jenkins Repository Github nachverfolgen und ausprobieren. Hier gibt es für jeden Abschnitt unter der in der Überschrift genannten Nummer jeweils für declarative und scripted einen Branch, der das vollständige Beispiel umfasst. Das Ergebnis der Builds jedes Branches lässt sich außerdem direkt auf der Cloudogu Jenkins-Instanz einsehen.
Umzug ins SCM /Jenkinsfile (1)
Einer der größten Vorteile von Jenkins Pipelines ist, dass man sie unter Versionsverwaltung stellen kann. Dazu ist es Konvention eine Datei Jenkinsfile ins Wurzelverzeichnis des Repositories zu legen. Dann kann der oben beschriebene Pipeline-Job auf „Pipeline script from SCM“ (siehe Abbildung 4) umgestellt oder ein Multibranch-Pipeline-Job angelegt werden.

Die URL des SCM (in diesem Fall Git) wird im Job konfiguriert. Man könnte die Pipeline-Scripts wie oben gezeigt einchecken, allerdings würde man dann die URL des Repositories im Repository wiederholen. Dies würde allerdings das DRY-Prinzip verletzen. Die Lösungen sind je nach Syntax unterschiedliche
- Declarative: Der Checkout wird standardmäßig durch die agent Section durchgeführt. Die Checkout Stage kann hier also komplett entfallen.
- Scripted: Der Checkout wird nicht standardmäßig ausgeführt. Es gibt jedoch die Variable scm, die die im Job konfigurierte Repository URL enthält, sowie den Step checkout, der den im Job konfigurierten SCM Provider (in diesem Falle Git) enthält.
stage('Checkout') {
checkout scm
}
Lesbarkeit mit eigenen Steps verbessern (2)
Groovy als Grundlage der Pipeline macht es sehr einfach die vorhandenen Steps zu erweitern. Am bestehenden Beispiel kann der Aufruf von Maven ausdrucksstärker gemacht werden, in dem er in eine eigene Methode gekapselt wird (siehe Listing 3).
def mvn(def args) {
def mvnHome = tool 'M3'
def javaHome = tool 'JDK8'
withEnv(["JAVA_HOME=${javaHome}", "PATH+MAVEN=${mvnHome}/bin:${env.JAVA_HOME}/bin"]) {
sh "${mvnHome}/bin/mvn ${args} --batch-mode -V -U -e -Dsurefire.useFile=false"
}
}
Listing 3
Diese erlaubt es sowohl in declarative als auch in scripted Syntax Maven wie folgt aufzurufen:
mvn 'package'
Die Definition der Tools wird in die Methode verlagert.
Durch die Auslagerung in eine Methode werden für die Ausführung auf Jenkins sinnvolle Maven Parameter (Batch Mode, Maven Version ausgeben, Snapshots updaten, fehlgeschlagenen Tests auf Konsole ausgeben) von den im Kontext des jeweiligen Aufrufs interessanten Maven Parametern (hier package-Phase) getrennt. Dadurch steigt die Lesbarkeit, weil man beim Aufruf nur die wesentlichen Parameter übergibt. Zudem muss man nicht die Parameter wiederholen, die ohnehin bei jedem Aufruf mitgegeben werden sollten.
Zusätzlich wird hier ein spezifisches JDK verwendet. Dies erfordert zwar, dass analog zu Maven unter „Global Tool Configuration“ nun eine JDK-Installation mit dem Namen JDK8 installiert wird. Dadurch wird jedoch der Build deterministischer, da nicht implizit das JDK von Jenkins verwendet wird, sondern ein explizit benanntes.
Diese Maven Methode ist den offiziellen Beispielen entnommen.
Eine Methode wie mvn ist ein guter Kandidat für die Auslagerung in eine Shared Library. Diese werden in einem folgenden Teil dieser Artikelserie beschrieben.
Unterteilung in Stages (3)
Ähnlich wie beim Schreiben von Methoden oder Funktionen in der Softwareentwicklung macht es auch für die Wartbarkeit von Pipeline-Scripts Sinn, kleine Stages zu verwenden. Diese Unterteilung erlaubt es bei scheiternden Builds mit einem Blick zu erkennen, wo etwas schief ging. Außerdem werden die Zeiten pro Stage gemessen, wodurch schnell ersichtlich wird, welche Teile des Builds am meisten Zeit benötigen.
Der Maven Build in diesem Beispiel lässt sich weiter unterteilen in Build und Unit Test. An dieser Stelle werden zudem erstmals Integration Tests ausgeführt. In diesem Beispiel erfolgt die Ausführung mit Arquillian und WildFly Swarm.
Wie das in declarative Syntax aussieht zeigt Listing 4.
stages {
stage('Build') {
steps {
mvn 'clean install -DskipTests'
}
}
stage('Unit Test') {
steps {
mvn 'test'
}
}
stage('Integration Test') {
steps {
mvn 'verify -DskipUnitTests -Parq-wildfly-swarm '
}
}
}
Listing 4
In scripted Syntax entfallen die steps Sections. Als Nachteil ist zu nennen, dass der gesamte Build dadurch etwas langsamer wird, da verschiedene Maven Phasen in mehreren Stages durchlaufen werden. Dies ist hier schon optimiert, indem clean nur einmal am Anfang aufgerufen wird und die pom.xml um ein Property skipUnitTests erweitert wird, was die erneute Ausführung der Unit Tests in der Integration Test Stage verhindert.
Bei Integration Tests besteht generell die Gefahr von Portkonflikten. Beispielsweise kann die Infrastruktur gleichzeitig laufender Builds an die gleichen Ports binden. Dadurch kommt es zu unerwartet fehlschlagenden Builds. Dies lässt sich durch die Verwendung von Docker© Technologien effektiv umgehen. Dies wird in einem folgenden Teil dieser Artikelserie beschrieben.
Ende des Pipeline-Laufs und Fehlerbehandlung (4)
Üblicherweise gibt es Schritte, die immer am Ende eines Pipeline-Laufs ausgeführt werden sollen, unabhängig davon, ob der Build erfolgreich war oder nicht. Das beste Beispiel dafür sind Testergebnisse. Schlägt ein Test fehl, sollte auch der Build fehlschlagen. In jedem Fall sollten aber die Testergebnisse in Jenkins erfasst werden.
Zudem sollte bei fehlschlagenden Builds oder wenn sich der Status des Builds ändert eine spezielle Reaktion erfolgen. Üblich ist hier das Versenden von Emails, denkbar wären aber auch Chat-Benachrichtigungen oder ähnliches.
Beide Fälle werden in Pipelines mit den ähnlichen syntaktischen Konzepten spezifiziert. Allerdings sind hier die Ansätze zwischen declarative und scripted Syntax unterschiedlich.
Generell stünden in beiden Fällen die Sprachmittel von Groovy, also try-catch-finally-Blöcke zur Verfügung. Diese sind allerdings nicht ideal, da gefangene Exceptions dann keine Auswirkungen auf den Build Status haben.
In der declarative Syntax stehen hier die post Section mit den Conditions always, changed, failure, success und unstable zur Verfügung. Damit lässt sich ausdrucksstark definieren, was am Ende jeder Ausführung passieren soll.
Das oben beschriebene Szenario lässt sich abbilden wie Listing 5 zeigt.
post {
always {
junit allowEmptyResults: true,
testResults: '**/target/surefire-reports/TEST-*.xml, **/target/failsafe-reports/*.xml'
}
changed {
mail to: "${env.EMAIL_RECIPIENTS}",
subject: "${JOB_NAME} - Build #${BUILD_NUMBER} - ${currentBuild.currentResult}!",
body: "Check console output at ${BUILD_URL} to view the results."
}
}
Listing 5
Erwähnenswert ist hier, dass man mit wenig Aufwand auch den bestehenden Email-Mechanismus von Jenkins verwenden kann, was später in diesem Abschnitt erklärt wird. Des Weiteren ist die Herkunft der Emailadresse der Empfänger hier von Relevanz. Im Beispiel werden diese aus der Environment Variable EMAIL_RECIPIENTS geladen. Diese muss von einem Administrator in der Jenkins Konfiguration festgelegt werden. Alternativ kann man die Empfänger natürlich auch direkt ins Jenkinsfile schreiben. Dann werden sie allerdings mit ins SCM eingecheckt.
In der scripted Syntax steht hier nur der catchError Step zur Verfügung. Dieser verhält sich im Wesentlichen wie ein finally Block. Um obiges Szenario abzubilden, muss hier mit if-Bedingungen gearbeitet werden. Auch hier empfiehlt es sich, aus Gründen der Wartbarkeit, einen eigenen Step zu definieren (siehe Listing 6).
node {
catchError {
// ... Stages ...
}
junit allowEmptyResults: true,
testResults: '**/target/surefire-reports/TEST-*.xml, **/target/failsafe-reports/*.xml'
statusChanged {
mail to: "${env.EMAIL_RECIPIENTS}",
subject: "${JOB_NAME} - Build #${BUILD_NUMBER} - ${currentBuild.currentResult}!",
body: "Check console output at ${BUILD_URL} to view the results."
}
}
def statusChanged(body) {
def previousBuild = currentBuild.previousBuild
if (previousBuild != null && previousBuild.result != currentBuild.currentResult) {
body()
}
}
Listing 6
Wie oben erwähnt, lässt sich das Thema Emails sowohl in der declarative als auch scripted Syntax vereinfachen, indem der bestehende Email-Mechanismus von Jenkins verwendet wird. Hier werden die bekannten „Build failed in Jenkins“ und „Jenkins build is back to normal“ Emails versendet. Dazu wird die Klasse Mailer verwendet, für die es keinen dedizierten Step gibt. Dies ist über den generischen Step step möglich. Wenn man auch die „back to normal“ Emails erhalten will, muss noch eine Besonderheit beachtet werden: Die Klasse Mailer liest den Wert aus der Variable currentBuild.result aus. In der Pipeline wird diese im Erfolgsfall erst ganz am Ende der Pipeline gesetzt. Dadurch erfährt die Klasse Mailer dies nie. Also bietet sich auch hier die Implementierung als eigener Step an. In scripted Syntax lässt sich dies realisieren wie in Listing 7 dargestellt. Die gleiche Lösung lässt sich aber auch mit declarative Syntax verwenden.
node {
// ... catchError und nodes
mailIfStatusChanged env.EMAIL_RECIPIENTS
}
def mailIfStatusChanged(String recipients) {
if (currentBuild.currentResult == 'SUCCESS') {
currentBuild.result = 'SUCCESS'
}
step([$class: 'Mailer', recipients: recipients])
}
Listing 7 Abschließend sei in Bezug auf Notification mit Hipchat, Slack, etc. der folgende Blogbeitrag von Jenkins empfohlen: Jenkins Notifications.
Properties und Archivierung (5)
Bei herkömmlichen Jenkins-Jobs gibt es viele kleinere Einstellungen, die man über die Oberfläche vornimmt, wie beispielsweise die Größe der Build-Historie, Verhindern paralleler Builds, etc. Selbstverständlich werden diese bei Verwendung des Pipeline Plugins im Jenkinsfile beschrieben. In der declarative Syntax werden diese Einstellungen als options bezeichnet. Dies gestaltet sich wie in Listing 8 dargestellt.
pipeline {
agent any
options {
disableConcurrentBuilds()
buildDiscarder(logRotator(numToKeepStr: '10'))
}
stages { /* .. */ }
}
Listing 8
In der scripted Syntax werden options als properties bezeichnet und über den gleichnamigen Step gesetzt (siehe Listing 9).
node {
properties([
disableConcurrentBuilds(),
buildDiscarder(logRotator(numToKeepStr: '10'))
])
catchError { /* ... */ }
}
Listing 9
Ein weiterer nützlicher Step ist archiveArtifacts. Er speichert durch den Build erstellte Artefakte (JAR, WAR, EAR, etc.), sodass diese über die Weboberfläche von Jenkins eingesehen werden können. Dies kann für Debugging nützlich sein oder tatsächlich zur Archivierung von Versionen, wenn man kein Maven Repository verwendet. In declarative Syntax lässt sich dies formulieren wie in Listing 10.
stage('Build') {
steps {
mvn 'clean install -DskipTests'
archiveArtifacts '**/target/*.*ar'
}
}
Listing 10
In scripted Syntax entfallen die steps Sections. Dies speichert alle JARs, WARs und EARs, die in einem der Maven Module erzeugt wurden.
Tipps für den Einstieg
Es gibt einige weitere grundlegende Directives, wie beispielsweise parameters (deklariert Build Parameter) und script (zum Ausführen eines Blocks in scripted Syntax innerhalb der declarative Syntax). Hier ist die Lektüre des Jenkins Pipeline Declarative Syntax empfehlenswert. Darüber hinaus gibt es viele weitere Steps, die im Wesentlichen durch Plugins bereitgestellt werden, siehe offizielle Übersicht. Damit diese in der Pipeline verfügbar sind, müssen Entwickler ein entsprechendes API verwenden. Die Pipeline-Kompatibilität einzelner Plugins ist hier zusammengefasst. Zum jetzigen Zeitpunkt haben die meisten gängigen Plugins Unterstützung für das Jenkins Pipeline Plugin.
Eine weitere empfehlenswerte Literatur sind die Top 10 Best Practices for Jenkins Pipeline.
Abschließend noch einige nützliche Tipps für die Arbeit mit dem Jenkinsfile. Beim ersten Aufsetzen einer Pipeline empfiehlt es sich mit einem normalen Pipeline-Job zu starten, und das Jenkinsfile erst unter Versionsverwaltung zu stellen, wenn der Build läuft. Ansonsten läuft man Gefahr seine Commit Historie zu verunreinigen.
Bei Änderungen einer bestehenden Multibranch-Pipeline bietet sich das „Replay“ Feature an, mit dem temporär für die nächste Ausführung die Pipeline über die Weboberfläche von Jenkins editieren kann, ohne das Jenkinsfile im SCM zu verändern. Ein letzter Tipp: Auch bei Pipelines kann man den Workspace über die Weboberfläche von Jenkins einsehen. Durch die agent Section bzw. den node Step ist es möglich, mehrere Build Executor zu belegen. Die wird mit dem Thema Parallelisierung in einem folgenden Teil dieser Artikelserie näher beschrieben. Deshalb kann es auch mehrere Workspaces geben. Diese kann man im classic Theme jeweils einsehen, indem man
- in eine Build Job auf „Pipeline Steps“ klickt und
- dort auf „Allocate node : Start“ klickt.
- Hier gibt es dann den bekannten „Workspace“-Link auf der linken Seite.
Fazit und Ausblick
Dieser Artikel gibt Einblick in die Grundlagen des Jenkins Pipeline-Plugin. Er beschreibt die Grundkonzepte und Begriffe, die verschiedenen Job-Arten, führt theoretisch und anhand von Beispielen in die Syntax des Jenkinsfile ein und gibt Praxistipps für das Arbeiten mit Pipelines. Wenn man die am Anfang des Artikels beschriebene Continuous-Delivery-Pipeline als roten Faden betrachtet, endet dieser Artikel bei 5. Das beschriebene Beispiel konfiguriert Jenkins, baut den Code, führt darauf Unit und Integration Tests aus, archiviert Testergebnisse sowie Artefakte und versendet Emails. Das alles mit einem ungefähr 30 Zeilen langen Script.
Um von Continuous Delivery zu sprechen, fehlen hier natürlich noch Schritte wie statische Code Analyse, beispielsweise mit SonarQube, und natürlich Deployments auf Staging und Produktivumgebungen. Um dies zu realisieren, bietet sich die Verwendung einiger Werkzeuge und Methoden an wie Nightly Builds, Wiederverwendung über verschiedene Jobs hinweg, Unit Testing, Parallelisierung und Docker© Technologien. Dies wird in folgenden Teilen dieser Artikelserie beschrieben.
Individuelle Beratung für Sie
Schaffen Sie mit uns den optimalen Rahmen für erstklassige Softwareentwicklung in Ihrem Unternehmen.
Zum GitOps Consulting

