


02.05.2018
in Technology
Coding Continuous Delivery — Performance Optimierung für die Jenkins Pipeline
Inhaltsverzeichnis
+++Der Originalartikel kann hier heruntergeladen werden: Zeitschriftenartikel, veröffentlicht in Java Aktuell 01/2018.+++
Nachdem der erste Teil dieser Artikelserie die Grundbegriffe und eine erste Jenkins Pipeline beschreibt, zeigt dieser Artikel wie man mittels Parallelisierung und Nightly Builds die Laufzeit der Pipelines verkürzen und damit schnelleres Feedback erhalten kann.
Im Folgenden werden die Pipeline-Beispiele aus dem ersten Artikel sukzessive erweitert, um die Features der Pipeline zu zeigen. Dabei werden die Änderungen jeweils in declarative und in scripted Syntax realisiert. Den aktuellen Stand jeder Erweiterung kann man bei GitHub nachverfolgen und ausprobieren. Hier gibt es für jeden Abschnitt unter der in der Überschrift genannten Nummer jeweils für declarative und scripted einen Branch, der das vollständige Beispiel umfasst. Das Ergebnis der Builds jedes Branches lässt sich außerdem direkt auf unserer Jenkins-Instanz einsehen.
Wie im ersten Teil, werden auch in diesem die Features des Jenkins Pipeline-Plugins anhand eines typischen Java Projekts gezeigt. Als Beispiel dient damit auch hier der kitchensink Quickstart von WildFly.
Da dieser Artikel auf den Beispielen aus dem ersten Artikel aufbaut, setzt sich die Nummerierung aus dem ersten Teil fort. Dort wurden mit simpler Pipeline, eigenen Steps, Stages, Fehlerbehandlung und Properties/Archivierung fünf Beispiele gezeigt. Deshalb ist Parallelisierung das sechste Beispiel.
Parallelisierung (6)
Dank des parallel Steps ist es sehr einfach, Steps oder Stages nebenläufig auszuführen und so die Gesamtlaufzeit der Pipeline zu verkürzen. Am einfachsten ist es dabei die Schritte parallel auf einem Node auszuführen. Dabei muss jedoch bedacht werden, dass die nebenläufigen Ausführungen im selben Verzeichnis laufen und sich dadurch unerwartet gegenseitig beeinflussen könnten. Beispielweise löschen zwei nebenläufig ausgeführte Maven Builds mit clean Phase dasselbe target Verzeichnis, wodurch ein Build wahrscheinlich scheitert.
Alternativ kann man auch mit mehreren Nodes parallelisieren, also mehrere Jenkins Build Executor belegen. Dies verursacht jedoch deutlich mehr Overhead. Es muss dann auf jedem Node der Workspace neu angelegt werden, also Git Clone, ggf. Maven Dependencies laden, etc. Daher ist die Parallelisierung innerhalb eines Nodes in den meisten Fällen die erste Wahl.
An dieser Stelle eine kleine Anekdote aus der Praxis zur Motivation für die Parallelisierung: In einem kleineren Projekt (ca. 10 KLOC) mit hoher Testabdeckung (ca. 80%) konnte die Build Dauer von 11 auf 8 Minuten verkürzt werden, indem die Unit- und Integrationstest-Stages parallel ausgeführt wurden. Des Weiteren konnte das ursprünglich sequenzielle Deployment von zwei Artefakten durch Parallelisierung von 4 auf 2,5 Minuten verkürzt werden. Es lohnt sich also den parallel Step im Hinterkopf zu behalten, um mit wenig Aufwand schnelleres Feedback zu bekommen.
Das Beispiel in Listing 1 zeigt in scripted Syntax, wie man die Unit- und Integrationstest-Stages gleichzeitig ausführt.
parallel(
unitTest: {
stage('Unit Test') {
mvn 'test'
}
},
integrationTest: {
stage('Integration Test') {
mvn 'verify -DskipUnitTests -Parq-wildfly-swarm '
}
}
)
Listing 1
Dem parallel Step wird eine Map übergeben, in der man die verschiedenen Ausführungszweige mit Namen versehen und in einem Closure definiert. Anhand des Namens können dann bei der Ausführung die Ausgaben im Log den jeweiligen Zweigen zugeordnet werden.
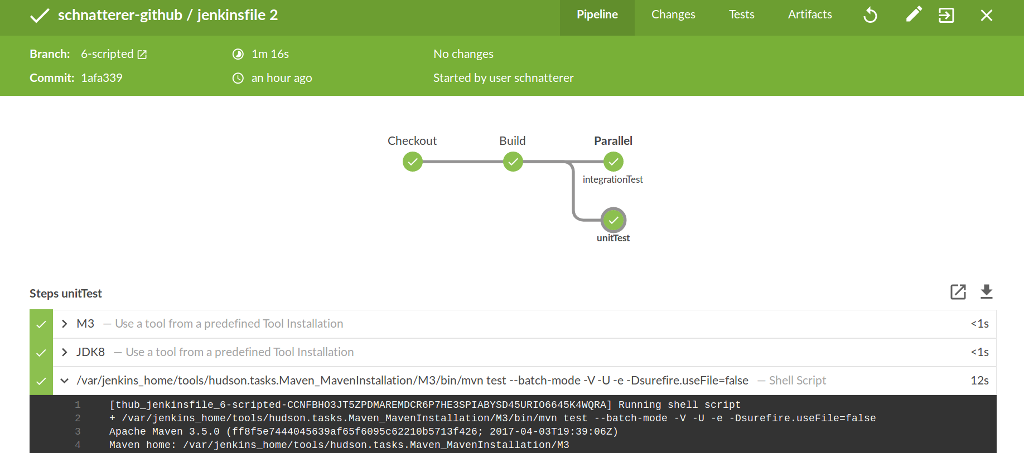
Hier spielt das schon im ersten Teil erwähnte Blue Ocean Plugin seine Stärken aus: Statt die Pipeline in einer Reihe anzuzeigen, wie in der klassischen Ansicht, werden gleichzeitig ausgeführte Zweige untereinander dargestellt (siehe Abbildung 1). Außerdem kann man sich die Konsolenausgabe der jeweiligen Branches isoliert ansehen und muss nicht, wie in der klassischen Ansicht, anhand des in der Pipeline vergebenen Namens unterscheiden (vergleiche Listing 2).
[integrationTest] [thub_`Jenkinsfile`_6-scripted-CCNFBHO3JT5ZPDMAREMDCR6P7HE3SPIABYSD45URIO6645K4WQRA] Running shell script
[integrationTest] + /var/jenkins_home/tools/hudson.tasks.Maven_MavenInstallation/M3/bin/mvn verify -DskipUnitTests -Parq-wildfly-swarm --batch-mode -V -U -e -Dsurefire.useFile=false
[unitTest] [thub_`Jenkinsfile`_6-scripted- CCNFBHO3JT5ZPDMAREMDCR6P7HE3SPIABYSD45URIO6645K4WQRA] Running shell script
[unitTest] + /var/jenkins_home/tools/hudson.tasks.Maven_MavenInstallation/M3/bin/mvn test --batch-mode -V -U -e -Dsurefire.useFile=false
Listing 2
Der parallel Step kann auch in der declarative Syntax verwendet werden. Listing 3 zeigt, wie sich dies über geschachtelte Stages abbilden lässt.
stage('Tests') {
parallel {
stage('Unit Test') {
steps {
mvn 'test'
}
}
stage('Integration Test') {
steps {
mvn 'verify -DskipUnitTests -Parq-wildfly-swarm '
}
}
}
}
Listing 3 Für komplexere Szenarien können zur Synchronisierung mehrerer gleichzeitiger Builds Locks und/oder das Milestone Plugin eingesetzt werden. Ein Beispiel das beides verwendet findet man hier.
Nightly Builds (7)
Viele Teams lassen ihren CI Server lang laufende oder regelmäßig aufzuführende Aufgaben einmal am Tag, typischerweise in der Nacht, erledigen. Ein Beispiel hierfür ist die Überprüfung ihrer Dependencies auf bekannte Sicherheitslücken (siehe Automatische Überprüfung von Sicherheitslücken in Abhängigkeiten von Java Projekten). Diese Nightly Builds sind auch in einer Jenkins Pipeline möglich.
Einen Build regelmäßig auszuführen ist dabei sehr einfach. Listing 4 zeigt, wie dies in der scripted Syntax über die im ersten Artikel beschriebenen Properties angegeben wird.
properties([
pipelineTriggers([cron('H H(0-3) * * 1-5')])
])
Listing 4
Bei der Ausführung des Jenkinsfiles werden dann die angegebenen Ausführungen von Jenkins eingeplant. In Listing 4 sieht man, dass wie in einer an Cron-Jobs angelehnten Syntax ein Schedule angegeben werden kann:
- Minute (0-59),
- Stunde (0-23),
- Tag des Monats (1-31),
- Monat (1-12),
- Tag der Woche (0-7), 0 und 7 sind Sonntag.
Der Asterisk (*) steht für „jeden validen Wert“. In Listing 4 bedeutet das beispielsweise “jeden Tag in jedem Monat“. Das H steht für den Hash des Job-Namens. Dabei wird ein Zahlenwert auf Basis des Hashwerts des Job-Namens generiert. Dies führt dazu, dass nicht alle Jobs mit gleichem Schedule zu Lastspitzen führen. Zum Beispiel würde
'0 0 * * 1-5'dazu führen, dass an jeden Werktag um Punkt 0 Uhr alle Jobs gleichzeitig loslaufen.'H H(0-3) * * 1-5'hingegen verteilt diese Last auf die Zeit zwischen 0 und 3 Uhr.
Diese Best Practice sollte so oft wie möglich verwendet werden.
Wem das zu kompliziert ist, dem stehen die Aliase @yearly, @annually, @monthly, @weekly, @daily, @midnight und @hourly zur Verfügung. Auch diese nutzen zur Lastverteilung das oben beschriebene Hash-System. Beispielsweise bedeutet @midnight konkret zwischen 0 und 2:59 Uhr.
Auf die gleiche Weise spezifiziert man den Schedule auch in der declarative Syntax (siehe Listing 5), allerdings wird diese hier in einer eigenen triggers Directive angegeben.
pipeline {
agent any
triggers {
cron('H H(0-3) * * 1-5')
}
}
Listing 5 Die größere Herausforderung liegt allerdings darin, zu entscheiden, wo man die nächtlich auszuführende Logik beschreibt. Hier bieten sich zwei Möglichkeiten.
Man legt ein weiteres Jenkinsfile im Repository an, beispielsweise Jenkinsfile-nightly. Außerdem legt man einen neuen Pipeline- oder Multibranch Pipeline Job in Jenkins an, gibt dort erneut das Repository an und den Namen des neuen Jenkinsfile, das gelesen werden soll. Der Vorteil ist, dass dies einfach aufzusetzen ist und eine gewisse Separation of Concerns bietet. Statt einem monolithischen Jenkinsfile mit sehr vielen Stages, die abhängig vom Trigger ausgeführt werden, hat man zwei Jenkinsfiles, bei denen immer alle Stages durchlaufen werden. Dies steht allerdings im Gegensatz zum Pipeline-Gedanken, bei dem jeder Build immer die gleichen Stages durchläuft. Des Weiteren lässt sich bei den beiden Pipelines eine gewisse Redundanz nicht vermeiden. Beispielsweise benötigt man meist in beiden die Build-Stage. Dieser Redundanz kann man zwar mit Shared Libraries oder dem load Step begegnen (siehe unten), trotzdem erhöht dies den Aufwand und die Komplexität. Außerdem ist ein zusätzlicher Job schwerer zu verwalten, insbesondere wenn man Multibranch Pipeline Jobs oder gar eine GitHub Organization betreibt. Dort werden pro Repository und Branch dynamisch neue Jobs angelegt (siehe ersten Teil der Artikelserie). Man hat dann mehrere Multibranch Build Jobs, bei GitHub Organizations sogar einen weiteren Multibranch Build Job pro Repository, die die Nightly Builds enthalten.
Alternativ pflegt man alle Stages in einem Jenkinsfile und unterscheidet welche Stages immer und welche nur nächtlich ausgeführt werden. Man kann zudem festlegen welche Branches nächtlich gebaut werden sollen. Dieser Ansatz entspricht dem Pipeline-Gedanken. Hier hat man dann die vollen Vorteile von Multibranch Pipeline Jobs, da jeder dynamisch generierte Branch auch nächtlich gebaut wird, wenn gewünscht. Im Moment hat dieser Ansatz noch den großen Nachteil, dass das Abfragen des Build Triggers umständlich ist.
Aufgrund der beschriebenen Nachteile eines weiteren Jobs liegt hier die Unterscheidung innerhalb des Jobs näher. Im Folgenden wird gezeigt, wie man dies praktisch realisieren kann.
Ähnlich wie bei den klassischen Freestyle Jobs, kann man in der Pipeline die Auslöser des Build (Build Causes) abfragen. Im Moment geht dies jedoch nur über das currentBuild.rawBuild Objekt. Den Zugriff darauf muss man sich von einem Jenkins Administrator freigeben lassen (Script Approval). Dies ist per Web auf https://JENKINSURL/scriptApproval/ oder direkt im Dateisystem unter JENKINS_HOME/script-approval.xml möglich. Jenkins empfiehlt den Zugriff auf das Objekt aus Sicherheitsgründen nicht freizugeben. Trotzdem ist dies derzeit die einzige Methode an die Build Causes zu kommen. Die Lösung dafür ist allerdings schon unterwegs: perspektivisch wird man die Build Causes direkt über das currentBuild Objekt abfragen können (siehe Jenkins Issue 41272), wofür kein Script Approval notwendig sein wird.
Dieses Script Approval vorausgesetzt, kann man beispielsweise die Ausführung der Integrationstests auf den Nightly Build beschränken (siehe Listing 6).
boolean isTimeTriggered = isTimeTriggeredBuild()
node {
// ...
stage('Integration Test') {
if (isTimeTriggered) {
mvn 'verify -DskipUnitTests -Parq-wildfly-swarm '
}
}
//...
}
boolean isTimeTriggeredBuild() {
for (Object currentBuildCause : script.currentBuild.rawBuild.getCauses()) {
return currentBuildCause.class.getName().contains('TimerTriggerCause')
}
return false
}
Listing 6
Auch hier ist die Logik für das Abfragen des Build Cause in einen eigenen Step ausgelagert. Auffällig ist, dass dieser Step außerhalb des Node aufgerufen wird. Man könnte diesen auch direkt in der Integration Test Stage abrufen. Allerdings würde man dann nicht die Aufforderung zum Script Approval bekommen, da diese vom Build Executor (Node) nicht zurück zum Master übertragen wird.
Um dieses Beispiel auszuführen, benötigt man die beiden Einträge aus Listing 7 in der script-approval.xml:
<approvedSignatures>
<string>method hudson.model.Run getCauses</string>
<string>method org.jenkinsci.plugins.workflow.support.steps.build.RunWrapper getRawBuild</string>
</approvedSignatures>
Listing 7
Wie oben beschrieben, kann man die Methoden auch per Web freigeben. Allerdings müssen die Methoden einzeln nacheinander zugelassen werden:
Build ausführen → Fehlschlag → getRawBuild zulassen → Build ausführen → Fehlschlag → getCauses zulassen → Build ausführen → Erfolg.
Wem das zu kompliziert ist, der kann sich auch mit dem in Listing 8 gezeigten Workaround behelfen.
boolean isNightly() {
return Calendar.instance.get(Calendar.HOUR_OF_DAY) in 0..3
}
Listing 8 Hier wird einfach anhand der Uhrzeit entschieden, ob der Build in der Nacht läuft. Dies hat den Nachteil, dass auch anders angestoßene Builds (beispielsweise durch SCM oder manuell gestartet) als Nightly Build betrachtet werden. Außerdem ist hierbei darauf zu achten, dass sich die Zeiten auf die Zeitzone des Jenkins- Servers beziehen.
Unabhängig vom Build Cause hat man immer die Möglichkeit nur bestimmte Branches in der Nacht zu bauen. Wie das in scripted Syntax aussieht, zeigt Listing 9.
node {
properties([
pipelineTriggers(createPipelineTriggers())
])
// ...
}
def createPipelineTriggers() {
if (env.BRANCH_NAME == 'master') {
return [cron('H H(0-3) * * 1-5')]
}
return []
}
Listing 9
In der declarative Syntax kann man dasselbe erreichen, muss dies aber anders ausdrücken. Hier gibt es die when Directive, mit der über die Ausführung einer Stage entschieden werden kann. In dieser kann man jedoch nur die von Jenkins oder einer Shared Library (siehe unten) bereit gestellten Steps verwenden. Innerhalb der Pipeline definierte Steps (wie isTimeTriggeredBuild() oder isNightly()) kann man nicht aufrufen. Allerdings kann der Code der Methoden dort direkt verwendet werden, wie Listing 10 zeigt.
stage('Integration Test') {
when { expression { return Calendar.instance.get(Calendar.HOUR_OF_DAY) in 0..3 } }
steps {
mvn 'verify -DskipUnitTests -Parq-wildfly-swarm '
}
}
Listing 10
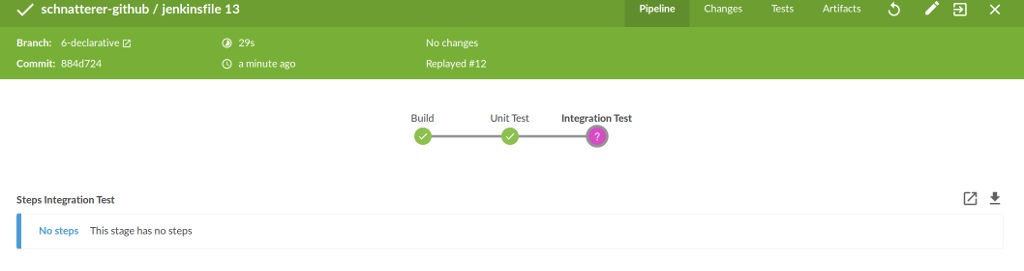
Ein Vorteil der declarative Syntax ist die bessere Integration in Blue Ocean. Wird eine Stage aufgrund des negativen Ergebnisses der when Directive übersprungen, wird dies in Blue Ocean entsprechend visualisiert (siehe Abbildung 2). Dies ist mit scripted Syntax nicht möglich.
Mit der declarative Syntax nur bestimmte Branches in der Nacht zu bauen, ist nicht intuitiv, denn die oben gezeigte triggers Directive kann nicht konditional ausgeführt werden. Als Notlösung bietet sich in der declarative Syntax der script Step oder das Aufrufen von selbst definierten Steps an. Dort kann man scripted Syntax ausführen. Damit lassen sich die Triggers in den scripted Properties festlegen. Nachteil ist, dass dies nur innerhalb einer Stage ausgeführt werden kann, wie Listing 11 zeigt.
Pipeline {
// ...
stages {
stage('Build') {
steps {
// ...
createPipelineTriggers()
}
}
}
// ...
}
void createPipelineTriggers() {
script {
def triggers = []
if (env.BRANCH_NAME == 'master') {
triggers = [cron('H H(0-3) * * 1-5')]
}
properties([
pipelineTriggers(triggers)
])
}
}
Listing 11
Individuelle Beratung für Sie
Schaffen Sie mit uns den optimalen Rahmen für erstklassige Softwareentwicklung in Ihrem Unternehmen.
Zum GitOps ConsultingFazit und Ausblick
Dieser Artikel zeigt wie man die Ausführungszeit der Pipeline verkürzen kann. Mittels Parallelisierung ist dies sehr einfach möglich. Eine weitere Möglichkeit ist die Auslagerung lang laufender Stages in den Nightly Build. Diese ist derzeit aber noch aufwändiger. Diese Konsolidierung der Pipeline ist ein Vorgeschmack auf den dritten Teil, in dem mit Shared Libraries und Docker© Tools weitere nützliche Werkzeuge vorgestellt werden. Diese vereinfachen den Umgang mit Pipelines durch Wiederverwendung über verschiedene Jobs hinweg, Unit Testing des Pipeline Codes und den Einsatz von Containern.


