


04/25/2018
in Quality
Crypto 101 basics
Table of Contents
+++ You can download the original article (German), published in Java Aktuell 01/2018.+++
Especially in DevOps-environment like ours, developers are increasingly coming into contact with cryptography. I have to admit: Cryptography is a very broad and complex topic requiring a good deal of knowledge and experience. In this blogpost, I would like to lay out practice-oriented fundamentals for everyday development work without diving too far into security-related aspects. I specifically included topics that I stumbled across myself when I first came into closer contact with cryptography. So let’s get started!
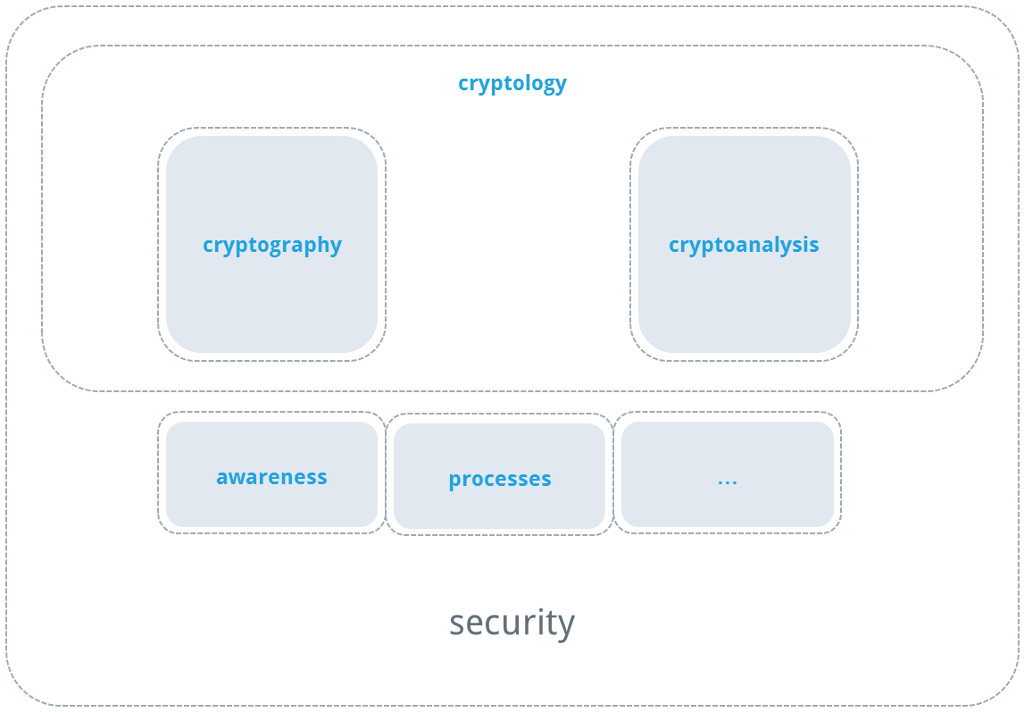
Cryptography deals with information security and is a subfield of cryptology. Another subfield is cryptanalysis, the goals of which include discovering vulnerabilities in existing cryptographic methods and quantifying the existing protection. Security, in turn, involves yet more topics alongside cryptography such as processes and handling of cryptographic methods, as well as awareness of such processes. For the sake of formality, I would like to also add that safety (in contrast to security) tends to describe (physical) integrity, and therefore belongs to a completely different field.
Cryptography is used to achieve 3 objectives:
- Confidentiality
- Certainty that messages cannot be read by third parties.
- Integrity
- Certainty that messages have not been modified from their original form.
- Authenticity
- Certainty that messages have originated from a sender who is known to me.
Cryptographic primitives
The objectives described in the section above are achieved through various operations, the so-called cryptographic primitives. They can be thought of as the basic arithmetic operations of cryptography.
- Cryptographic Hash One-way functions that are above all collision-resistant, along with other features.
- Symmetric Encryption Encryption method in which the same key is used for both the encryption and the decryption. These techniques are typically very fast.
- Asymmetric Encryption Encryption method in which there are two keys that are interdependent from each other. For each key, the other key allows the inversion of an operation. This is also known as public-key cryptography. These techniques are typically slower than symmetric methods.
- Digital Signature Ensures the authenticity and integrity of a message. Explained simply, this technique uses asymmetric encryption of the hash of a message.
- Cryptographically Secure Random Number Generation It is not surprising that true randomness cannot be produced by a deterministic machine. Cryptographic algorithms use nonces (numbers that shall only be used once) or initialization vectors (initial block for block ciphers). They are typically randomly generated and thus impact the security of higher-level operations.
- Other There are even more primitives out there that I do not wish to discuss here. One good starting point for those interested is the identically named Wikipedia article.
A combination of such primitives is called a cryptosystem. The mode of combination depends on the use case, for example Transport Layer Security (TLS) or Secure Shell (SSH).
Reliability of cryptography
The reliability provided by cryptographic algorithms is based in large part on one-way functions. As the name suggests, these are functions for which there is (so far) no efficient inverse function. Examples of one-way functions, besides cryptographic hashing functions, are the multiplication of prime numbers (the basis for RSA), the discrete exponential function in finite fields, and the multiplication of points on elliptic curves (the basis for the ElGamal method and the Diffie-Hellman method). Kerckhoff’s principle states that the security of cryptographic methods must not depend on the secrecy of the method. Instead, it must depend on the secrecy of the key. This makes it possible to disprove the security of the system and allow for insecure methods to be avoided. The converse of this is commonly referred to as “Security by Obscurity.” Vulnerabilities in cryptosystems either originate directly with the specification (BEAST) of a method or in the specific implementation of a method (Heart Bleed). Implementations can also make side-channel attacks possible, in which inferences can be made from the processing time required for an operation, for example.
Securely storing passwords
Storing a user-selected password in plain text is a “no-go”—most developers know that. But how exactly should passwords be stored then? I have often heard the term encryption used in this context, which typically means one of two things. Either the storage of passwords is made more complicated, since another “password” must now also be stored for encrypting the user-selected password, or the term encryption is used in error and hashing is what is really meant. Due to the fact that hashes are deterministic one-way functions, they are very well suited to securing passwords. However, simple hash tables can therefore be generated in order to save corresponding hashes in association with their plain text source. In this way, a time-efficient (but storage inefficient) inverse function is created. In the event that one has an entire database with hashed passwords (for example due to infiltration of a system), an additional problem arises. If an attacker guesses passwords and hashes them (expensive), all available passwords can be checked against these (less computationally expensive), thereby attacking all passwords in a single step. The remedy for this is a so-called salt. Salts are randomly and individually generated for each password. They are stored along with the password and extend the password prior to hashing. As a result, passwords differ from each other by at least their salt, which has two important effects. First, an attacker can no longer simply compare two datasets to look for a password match of the hash. Second, it is now impossible to check all passwords in a database simultaneously. Hashing functions are, however, also used on much larger volumes of data for other purposes, which is why one of the explicit development goals for some hashing functions is performance. This is unbelievably handy for calculating a hash from a Linux image as well as for testing passwords through brute force. Therefore, an important feature of password hashing functions is slowness. One simple solution is repeated use of a hashing function. A better alternative is a hashing function that is designed to have configurable slowness. If a hashing function also requires a lot of RAM, parallelization or the use of special hardware becomes uneconomical. One hashing function that is suitable for passwords is bCrypt. From a salt, a cost factor, and the password, it generates a string that contains both the salt and the hash. 12 is a good cost factor for the time being. At Security-Stackexchange, you will find a very detailed answer that gives an in-depth description of other good hashing functions.
SSH host authentication
Most developers have at some point logged into a server via SSH. When connecting to an SSH server for the first time, you are typically asked whether you want to trust the server—of course that’s what you want, right? Or maybe not? When starting the connection, the server introduces itself by providing its public key. Using the public key, the client can decide whether it wants to continue connecting to the server based on recognition of the key—basically like the guest list for a VIP party. As the handshake continues, the server verifies that it has the corresponding private key.

Ideally, the exchange of the public key is made via a channel that is separate from the first connection, since this public key is the trust anchor for client authentication of the server. One option is a USB stick. If this is not possible, one should get confirmation of the fingerprint (hash) of the public key from the administrator (by phone, for example) in order to ensure that no connection is made to a fake server. This is certainly less critical for a home-built Raspberry Pi than for connecting to a remote backup server for transferring a backup.
TLS host authentication
The number of SSH servers that one regularly connects to is manageable. The situation is different for websites. Saving each public website key in advance is simply impractical. Nevertheless, there is a need to decide whether a website actually is the one it claims to be, particularly if credit card data or other sensitive information are exchanged. To do this, the concept of key pairs is simply expanded several degrees and the result is a certificate chain. Instead of a public key for each server, a public key from a certificate authority (CA) is used. This public key is signed with the corresponding private key and is called the root certificate. Other public keys are signed with this specific private key, forming what are called intermediate certificates. There are typically multiple classes of intermediate certificates. The purpose of these is essentially to make it so that the central private key is taken out of the vault as rarely as possible. A key pair is either intended for the creation of other intermediate certificates or for use by a website.
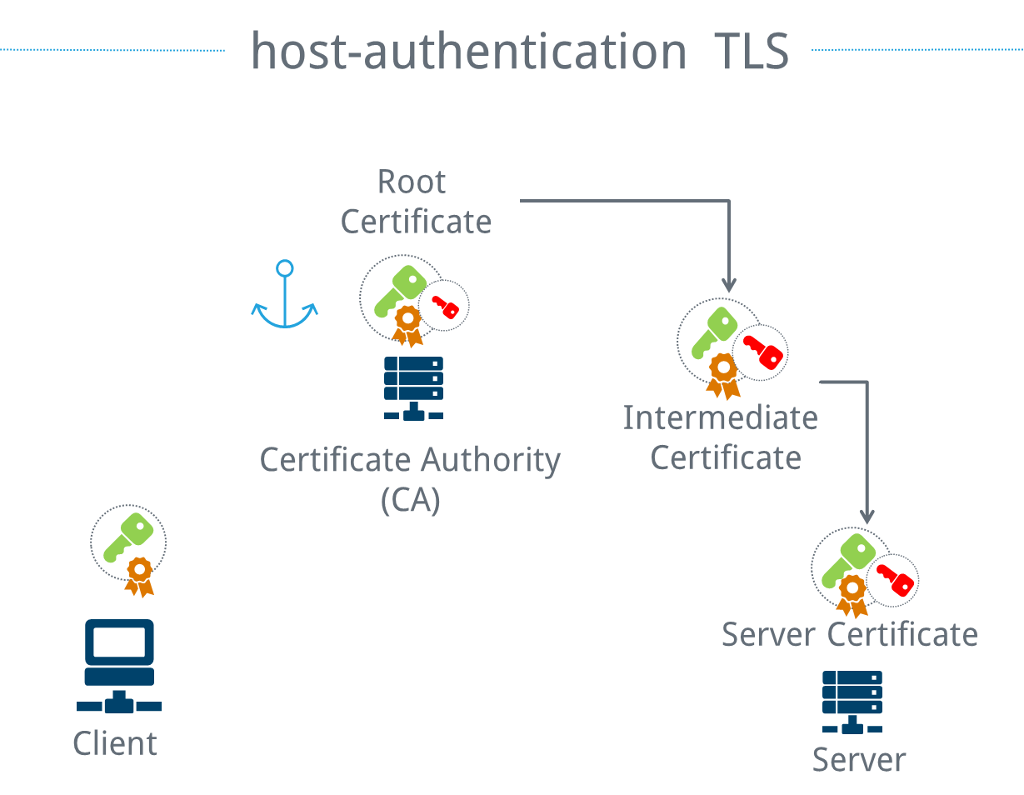
By chaining the certificates, the client only needs to trust the root certificate and can still ensure that the web server is the correct one. In short, this means that a certificate is the public key of an asymmetric method, which in turn was signed using an asymmetric method. A certificate signing request (CSR) is used to request that a public key be signed while simultaneously providing proof that the requestor possesses the corresponding private key. The CSR also contains additional information, such as the URL of the website for which the certificate is intended, and who is making the request.
Cipher suites for the TLS example
Instructions on the configuration of web servers regularly contain strings that are unreadable at first glance, such as ECDHE_RSA_WITH_AES_256_CBC_SHA384.
It is general knowledge that TLS connections are encrypted. The specific encryption method used is set by the cipher suite, however. In the example above, the encryption is performed using AES (CBC mode, 256bit key). Additionally, an HMAC based on SHA-384 is generated that ensures the integrity and authenticity of the confidential content.
But where does that 256bit key that must be known to the server and the client come from? It is generated using the Diffie-Hellman method, based on the discrete exponential function along elliptic curves. This mathematical technique makes it possible for two parties to agree on a truly secret key over an insecure connection. Furthermore, the browser uses the RSA method to check whether the server is actually the one that it claims to be with its certificate. At this point, the server must prove that it has the correct private key.
Key generation and certificate verification take place as part of the TLS handshake, and serve as the basis for the symmetrically encrypted communication that follows.
In very general terms, a cipher suite determines which cryptographic primitives are used for a given protocol. The actual protocol governs, which elements are necessary. For instance, even the cipher suites used in TLS 1.2 and TLS 1.3 differ from each other.
Additional material and tools
Independent of the question of whether passwords are stored in a sufficiently secure manner by the application, my recommendation is to never allow weak passwords and make sure that strong passwords are possible (this includes not limiting passwords to 12 characters). The OWASP Password Storage Cheat Sheet is an excellent read to decide on a password policy. passay provides easy implementation for a given policy in Java applications. There also is a Cheat Sheet on how to handle forgotten passwords created by OWASP. Bouncy Castle is useful if the application use case itself involves cryptography. It also includes an implementation of bCrypt. A low-level introduction to secure configuration for common webservers is available through the Mozilla Config Generator . The configuration can then be tested using the Qualys SSL Lab Server Test. As a side note, this test can also be automated very well with the monitoring tool of your choice by using the official API. When deciding which method can be used and how many bits a key should have, keylength.com is helpful. The recommendations of NIST and BSI (among others) are compiled there. Bruce Schneier’s blog is full of information on the topic of security from the perspective of a very experienced cryptographer.
Conclusion
The basic concepts underlying the cryptographic topics introduced here are relatively easy to digest. I have purposefully left many details out in order to make such an overview possible. Any detailed discussion quickly becomes quite lengthy. I’d like to leave you with two principles that you should take to heart when working with cryptography.
- homemade is bad
- new is bad
This basically means that any method applied needs to be thoroughly tested, which is typically not the case for new or homemade methods. The links provided are helpful for preparing secure web servers with only a bit of effort and are generally what we make use of with respect to our own applications here at cloudogu. An accompanying presentation to this article is also available on my Speaker Deck – you can also get in touch in with us, if you’re interested in a live presentation :)


